1.18 Conditional jumps
1.18.1 Simple example
#include <stdio.h> // include the standard I/O header; this directive includes the header file for standard input/output functions
void f_signed (int a, int b) // define signed comparison function; takes two int parameters
{
if (a > b) // check if a is greater than b
printf("a>b\n"); // print "a>b" followed by newline if condition true
if (a == b) // check if a equals b
printf("a==b\n"); // print "a==b" followed by newline if condition true
if (a < b) // check if a is less than b
printf("a<b\n"); // print "a<b" followed by newline if condition true
};
void f_unsigned (unsigned int a, unsigned int b) // define unsigned comparison function; takes two unsigned int parameters
{
if (a > b) // check if a is greater than b (unsigned)
printf("a>b\n"); // print "a>b" followed by newline if condition true
if (a == b) // check if a equals b
printf("a==b\n"); // print "a==b" followed by newline if condition true
if (a < b) // check if a is less than b (unsigned)
printf("a<b\n"); // print "a<b" followed by newline if condition true
};
int main() // program entry point
{
f_signed(1, 2); // call f_signed with arguments 1 and 2
f_unsigned(1, 2); // call f_unsigned with arguments 1 and 2
return 0; // return 0 to indicate successful termination
};
x86
x86 + MSVC
This is the form of the f_signed() function:
Listing 1.110: MSVC 2010 without optimization
a$ = 8 ; parameter a offset
_b$ = 12 ; parameter b offset
_f_signed PROC ; start of f_signed procedure
push ebp ; save base pointer
mov ebp, esp ; set up stack frame
mov eax, DWORD PTR _a$[ebp] ; load a into EAX
cmp eax, DWORD PTR _b$[ebp] ; compare a with b
jle SHORT $LN3@f_signed ; jump if a <= b
push OFFSET $SG737 ; 'a>b' ; push address of string "a>b\n"
call _printf ; call printf
add esp, 4 ; clean up stack
$LN3@f_signed: ; label
mov ecx, DWORD PTR _a$[ebp] ; load a into ECX
cmp ecx, DWORD PTR _b$[ebp] ; compare a with b again
jne SHORT $LN2@f_signed ; jump if a != b
push OFFSET $SG739 ; 'a==b' ; push address of string "a==b\n"
call _printf ; call printf
add esp, 4 ; clean up stack
$LN2@f_signed: ; label
mov edx, DWORD PTR _a$[ebp] ; load a into EDX
cmp edx, DWORD PTR _b$[ebp] ; compare a with b again
jge SHORT $LN4@f_signed ; jump if a >= b
push OFFSET $SG741 ; 'a<b' ; push address of string "a<b\n"
call _printf ; call printf
add esp, 4 ; clean up stack
$LN4@f_signed: ; label
pop ebp ; restore base pointer
ret 0 ; return
_f_signed ENDP ; end of procedure
We will talk first about the first instruction which is JLE and this means (Jump if Less or Equal)
Meaning if the operand if the second operand is greater than or equal to the first, the execution will jump to the address or the label that is in the instruction. If this condition is not met (meaning the second operand is smaller than the first), the execution will not change, and the first printf() will be executed
The second check is JNE : Jump if Not Equal.
Meaning the execution will not jump if the two values are equal.
The third check is JGE : Jump if Greater or Equal
Meaning jump if the first operand is greater than the second or equal to it.
So if these three conditional jumps are met,
Not a single printf() will be executed at all.
And this is impossible to happen without special intervention.
And because this part confused me a bit too I will explain it to you one by one simply
The compiler does not write the same condition as in C it does the opposite
Meaning for example when we come to the first condition which was if (a > b) then the compiler if the condition is not a>b jump and pass normally
And here the sentence “not a>b” will mean a<=b
That's why it was in Assembly JLE ; Jump if Less or Equal and so on for the rest
For now let's go look at the f_unsigned() function
This function is exactly like f_signed() , the only difference is that the instructions JBE and JAE are used instead of JLE and JGE
Like this:
a$ = 8 ; size = 4 ; parameter a offset
_b$ = 12 ; size = 4 ; parameter b offset
_f_unsigned PROC ; start of f_unsigned procedure
push ebp ; save base pointer
mov ebp, esp ; set up stack frame
mov eax, DWORD PTR _a$[ebp] ; load a into EAX
cmp eax, DWORD PTR _b$[ebp] ; compare a with b
jbe SHORT $LN3@f_unsigned ; jump if a <= b (unsigned)
push OFFSET $SG2761 ; 'a>b' ; push address of string "a>b\n"
call _printf ; call printf
add esp, 4 ; clean up stack
$LN3@f_unsigned: ; label
mov ecx, DWORD PTR _a$[ebp] ; load a into ECX
cmp ecx, DWORD PTR _b$[ebp] ; compare a with b again
jne SHORT $LN2@f_unsigned ; jump if a != b
push OFFSET $SG2763 ; 'a==b' ; push address of string "a==b\n"
call _printf ; call printf
add esp, 4 ; clean up stack
$LN2@f_unsigned: ; label
mov edx, DWORD PTR _a$[ebp] ; load a into EDX
cmp edx, DWORD PTR _b$[ebp] ; compare a with b again
jae SHORT $LN4@f_unsigned ; jump if a >= b (unsigned)
push OFFSET $SG2765 ; 'a<b' ; push address of string "a<b\n"
call _printf ; call printf
add esp, 4 ; clean up stack
$LN4@f_unsigned: ; label
pop ebp ; restore base pointer
ret 0 ; return
_f_unsigned ENDP ; end of procedure
As said before, the jump instructions here are different:
* JBE = Jump if Below or Equal
* JAE = Jump if Above or Equal
These instructions (JA / JAE / JB / JBE) differ from
(JG / JGE / JL / JLE)
In that they work with unsigned numbers.
And therefore, if we see:
* JG / JL used → probably the variables are signed
* JA / JB used → probably the variables are unsigned
And finally, this is the main() code, and there is nothing new for us in it:
_main PROC ; start of main procedure
push ebp ; save base pointer
mov ebp, esp ; set up stack frame
push 2 ; push argument 2 (b)
push 1 ; push argument 1 (a)
call _f_signed ; call f_signed
add esp, 8 ; clean up stack (two pushes)
push 2 ; push argument 2 (b)
push 1 ; push argument 1 (a)
call _f_unsigned ; call f_unsigned
add esp, 8 ; clean up stack
xor eax, eax ; set EAX to 0 (return value)
pop ebp ; restore base pointer
ret 0 ; return
_main ENDP ; end of main procedure
x86 + MSVC + OllyDbg
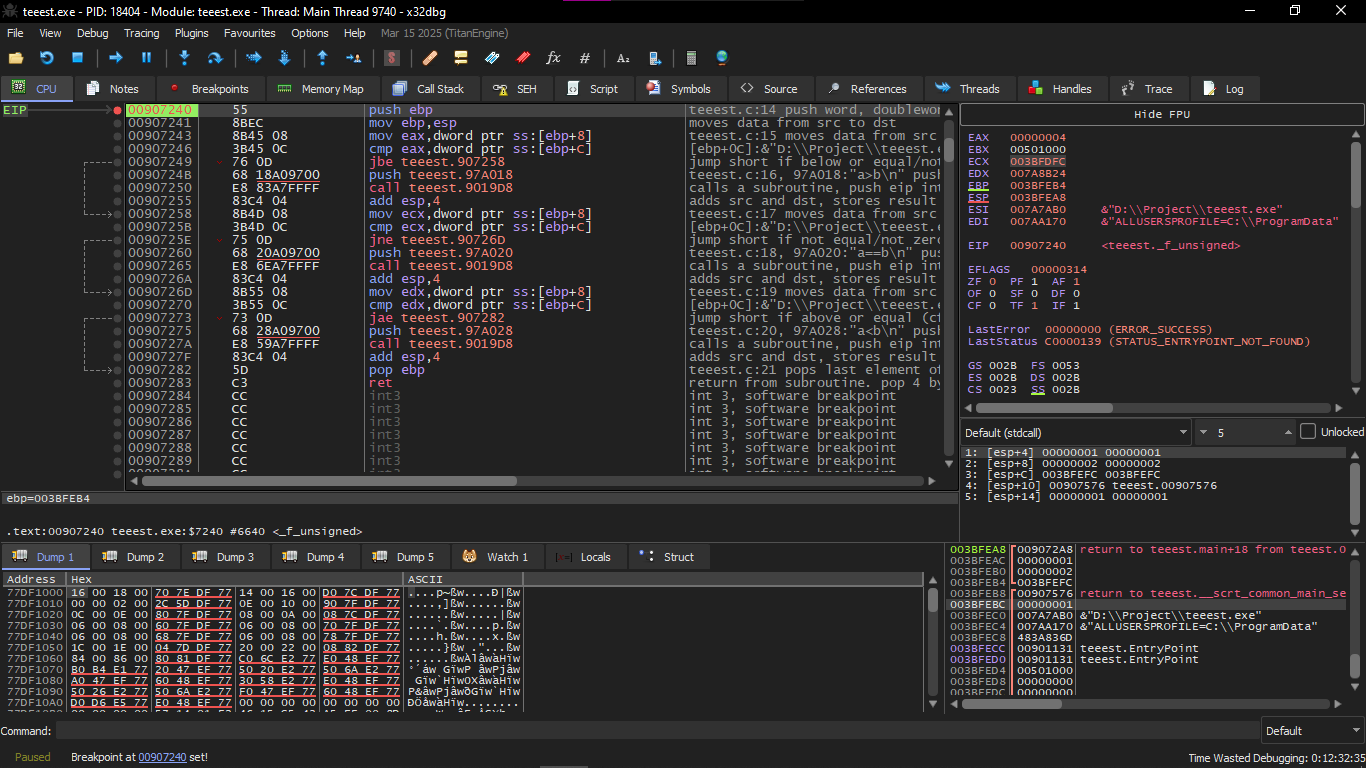
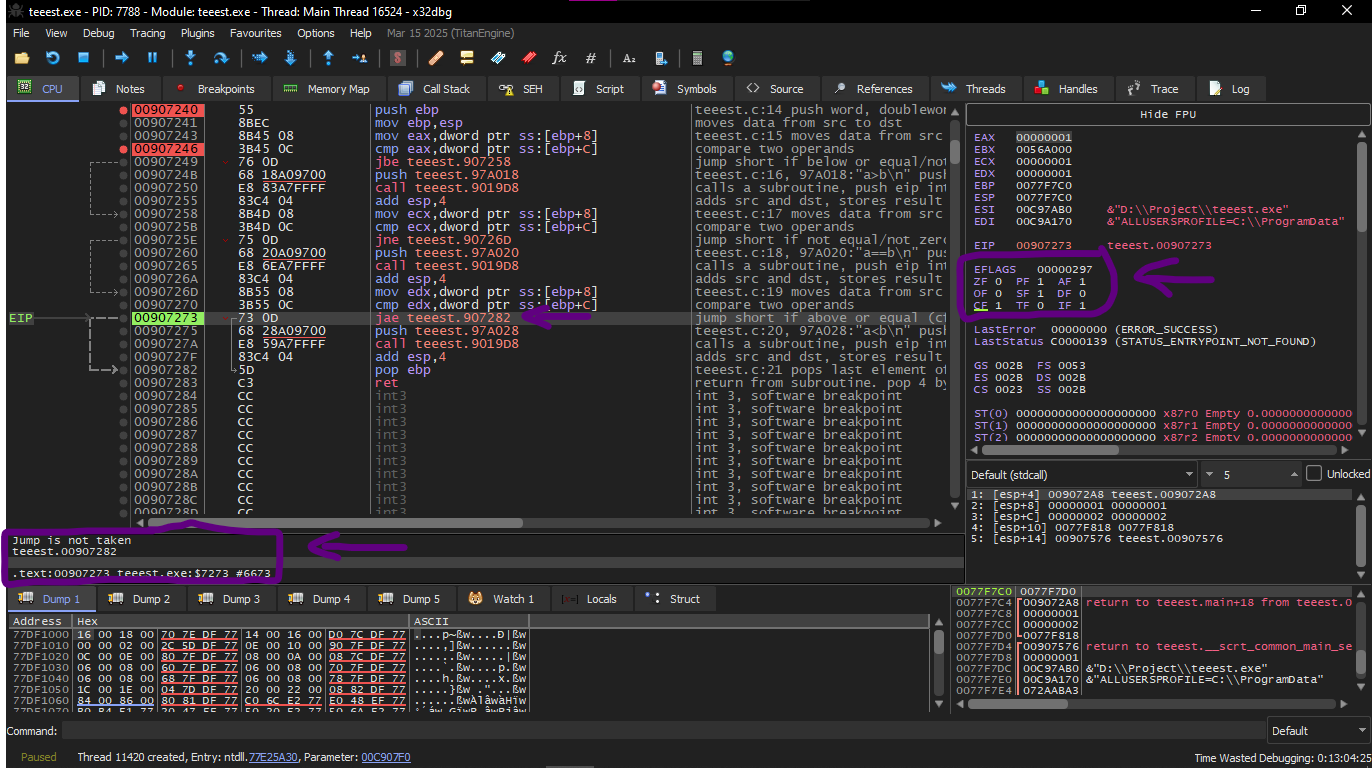
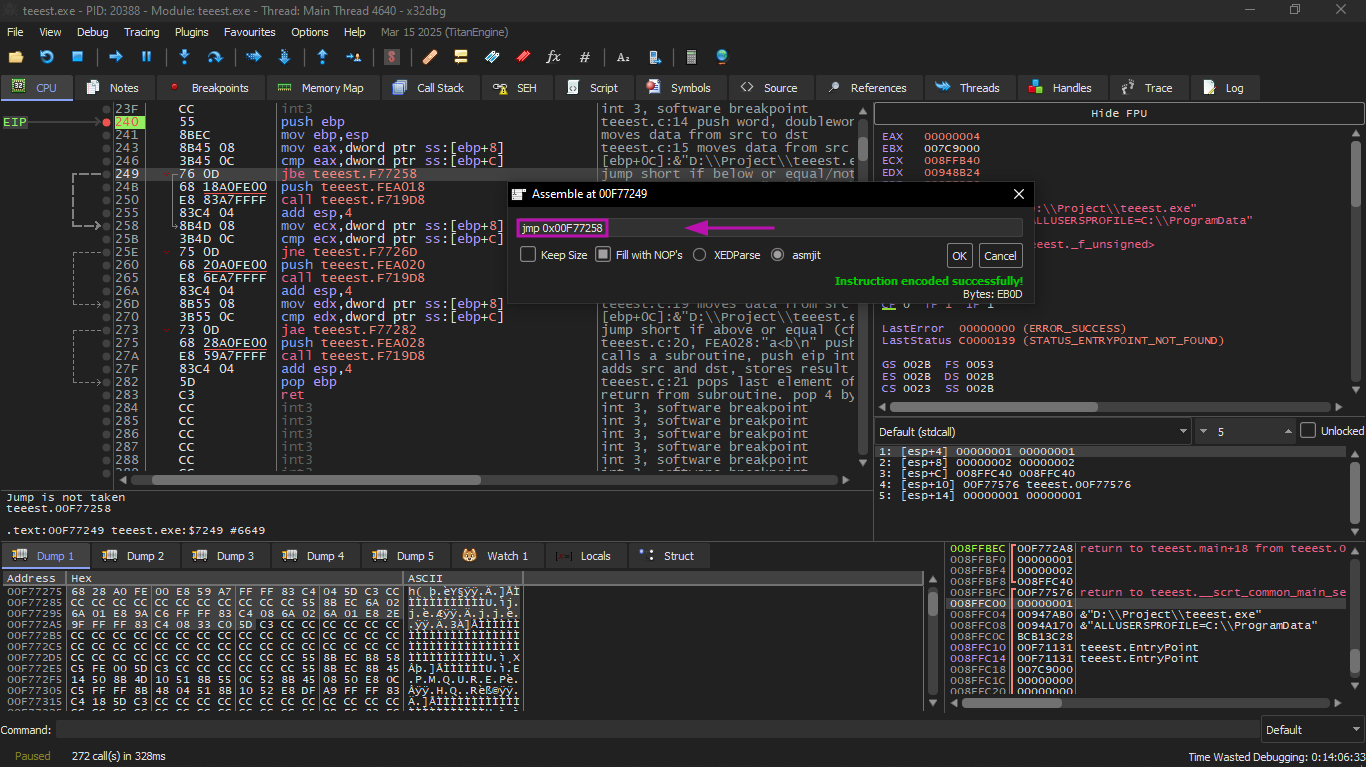
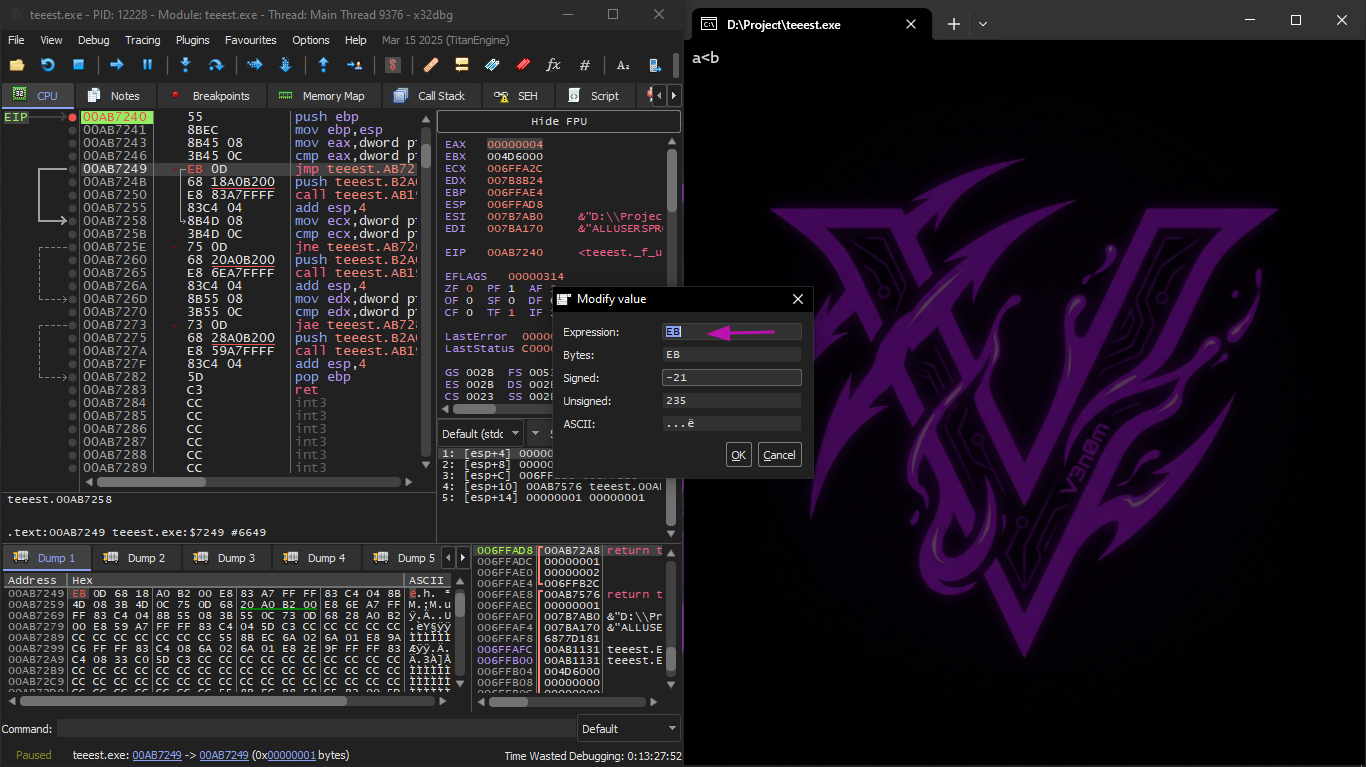
We will do this example also on x32dbg as usual
And as every time we will compile and then open it on x32dbg and enter the first function whose name is f_unsigned
We will set a breakpoint on this instruction
And this performs a fake subtraction and sees the result and adjusts the Flags on it
Well what are the Flags anyway quickly?
They are some things that alert inside the processor each one of them says something about the last arithmetic operation
And these are the most important 4 Flags in this example
| Flag | meaning |
|---|
| CF | borrow happen (important for unsigned) |
| ZF | result zero |
| SF | result negative |
| OF | overflow in signed |
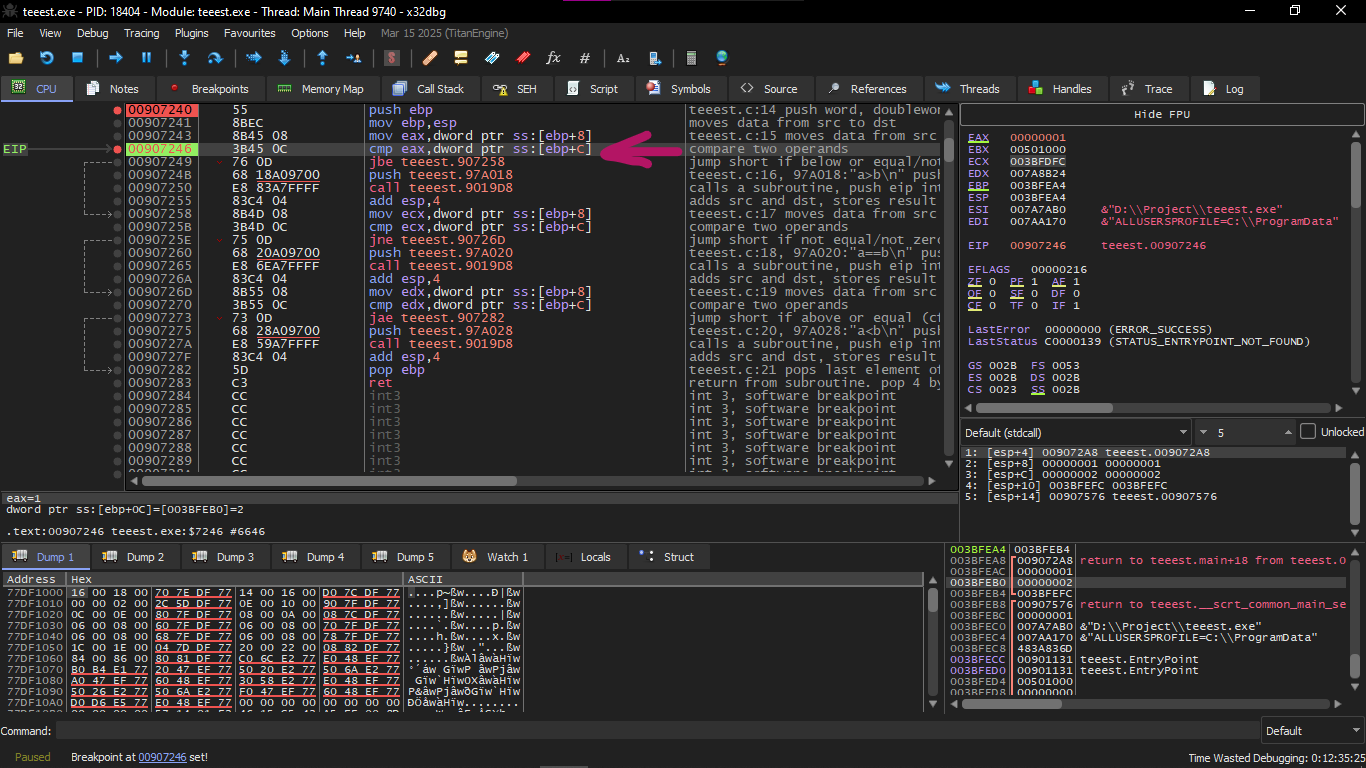
Here we explain what happened one by one
The values :
a = 003BFDFC
b = 00000001
CMP does:
What does the processor see?
* Did borrow happen? → yes → CF = 1
* Is the result zero? → no → ZF = 0
* Is the highest bit = 1? → yes → SF = 1
* Is signed overflow? → no → OF = 0
Then the Flags will be like this
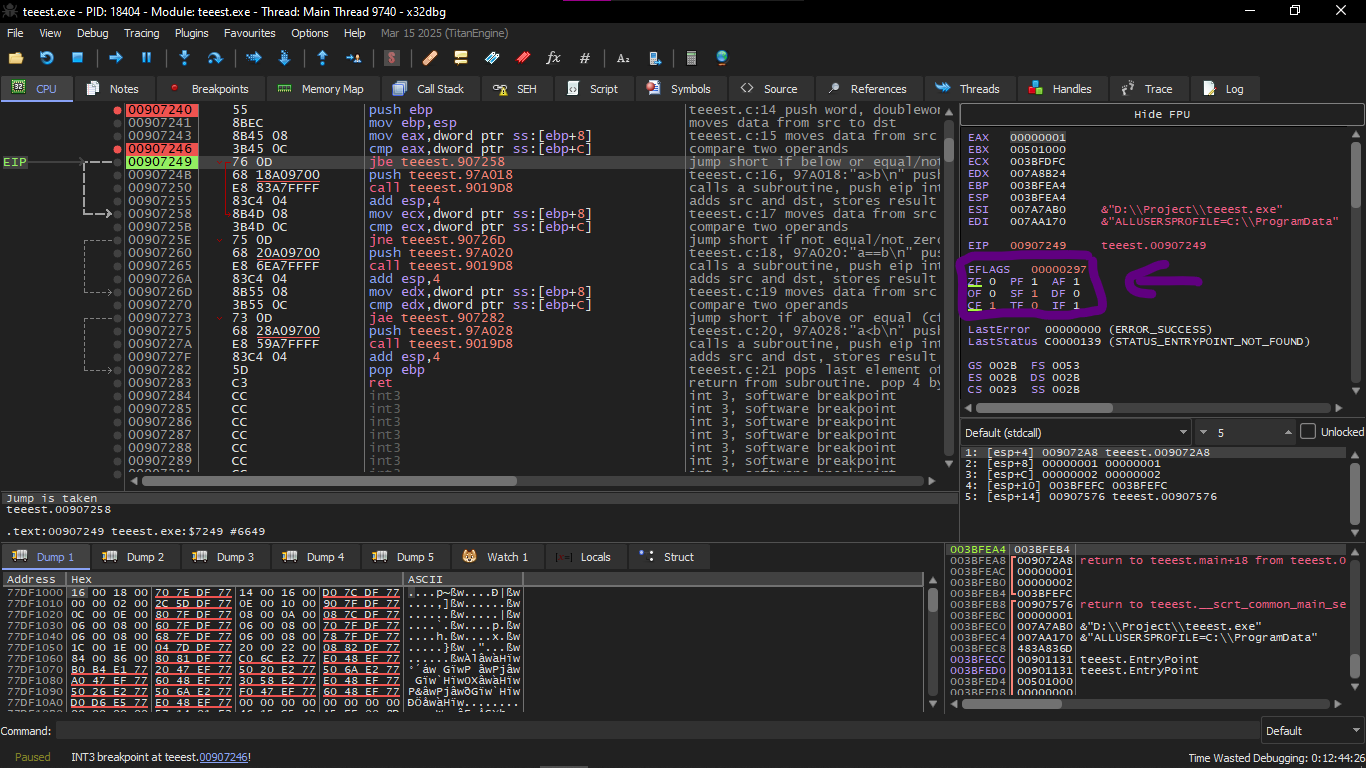
After that we enter the second jump
Here x32dbg gave a hint that JNZ will activate and this is correct, because JNZ activates when ZF=0 (zero flag)
After that third conditional jump
We will find that JNB activates when CF=0 (carry flag).
And this is not happening in our case, so the third printf(), will be executed.
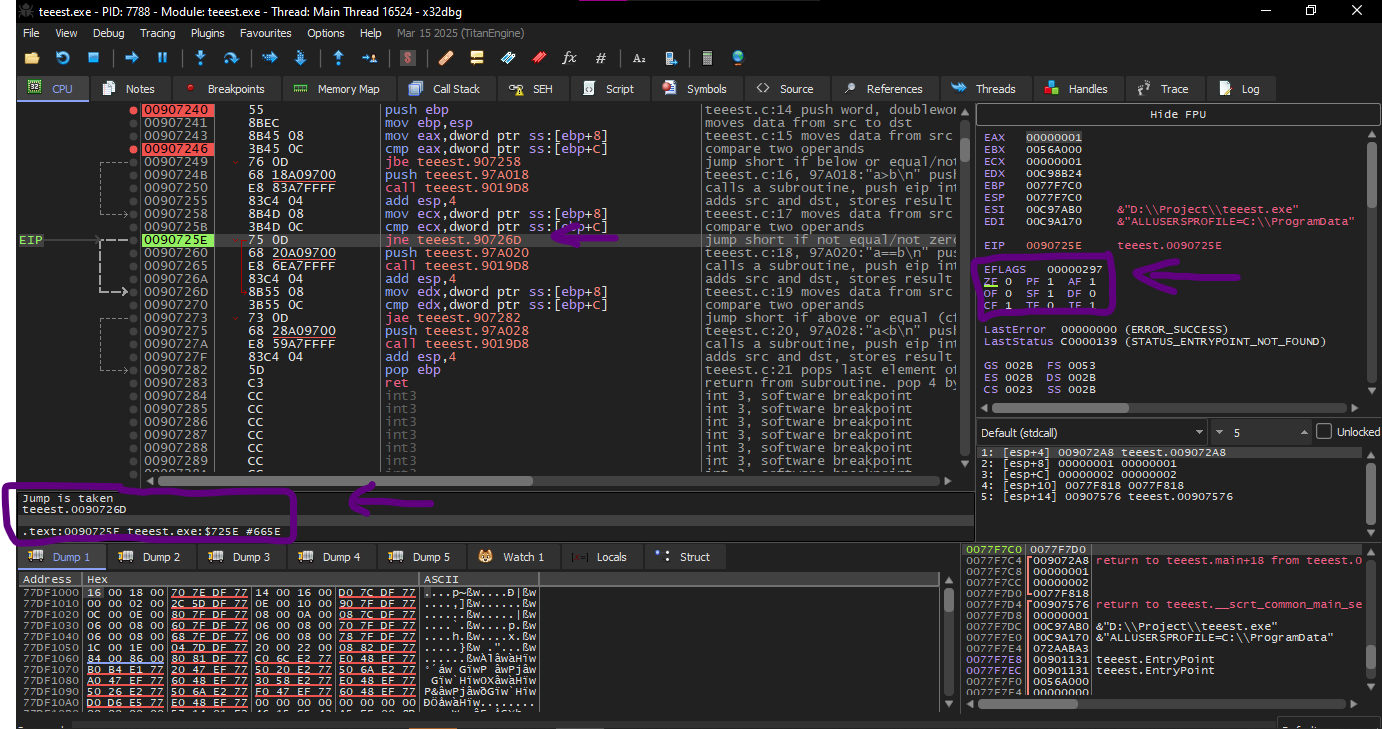
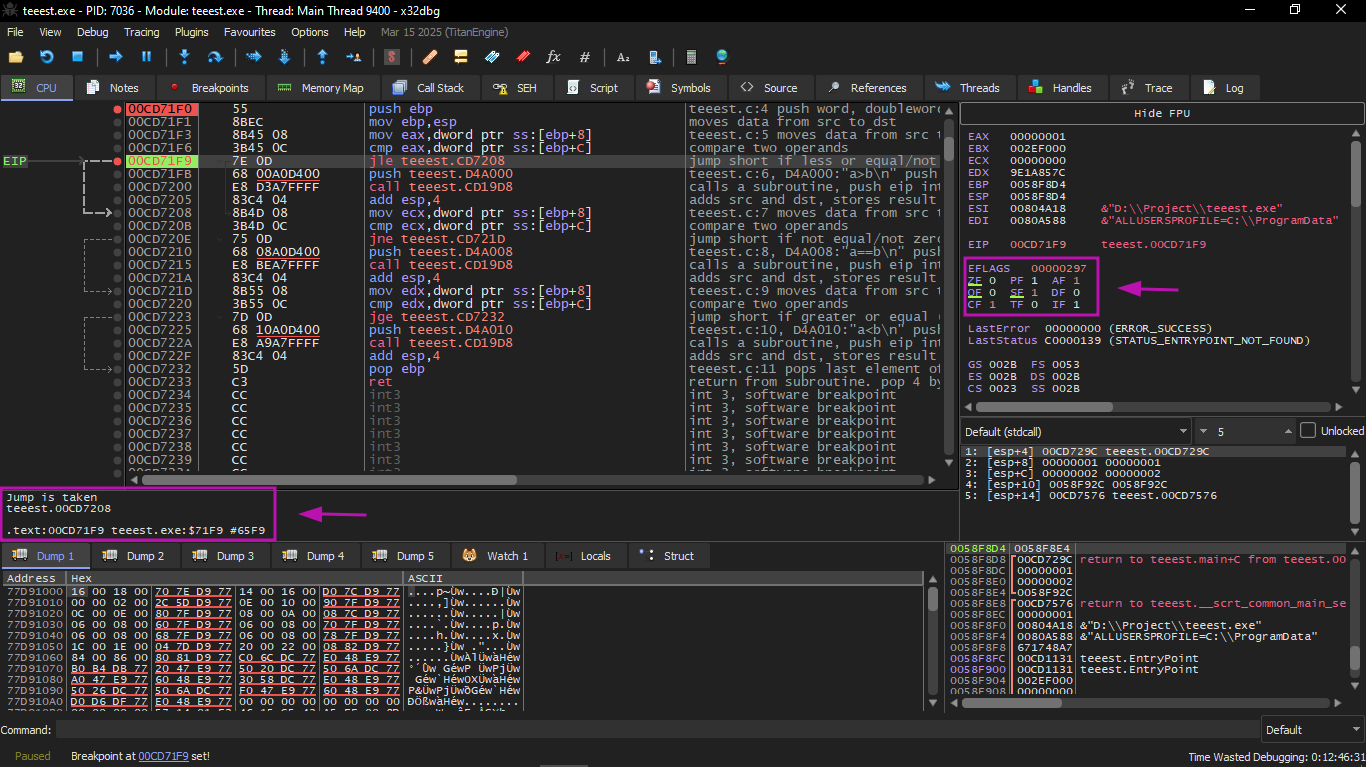
Now we come to f_signed() which deals with signed numbers
First conditional jump: JLE
Here in this jump the flags are adjusted in the same way
CF=1, PF=1, AF=1, ZF=0, SF=1, TF=0, DF=0, OF=0
In Intel manuals it is written that this instruction is executed if:
ZF=1 or SF≠OF
In our case SF≠OF, so the jump is executed.
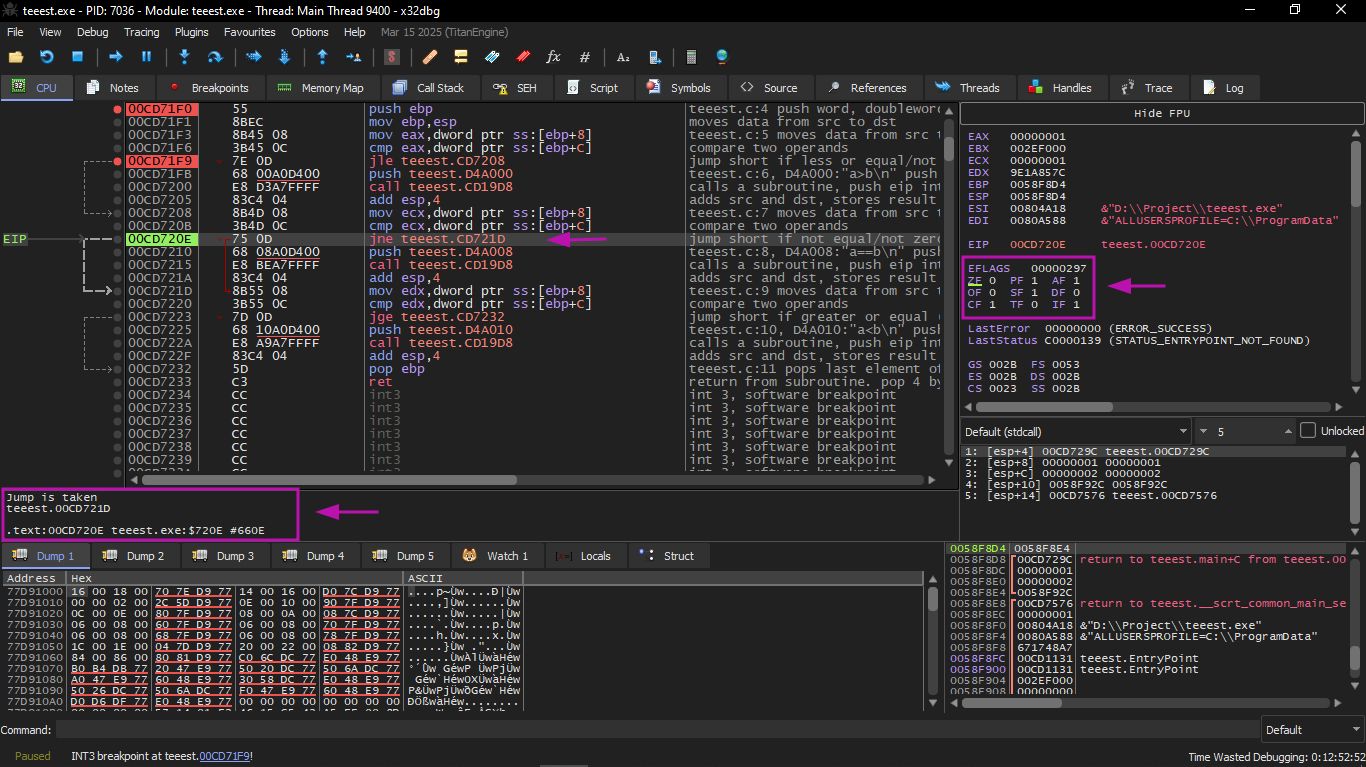
The second conditional jump: JNZ
Is executed if :
ZF=0
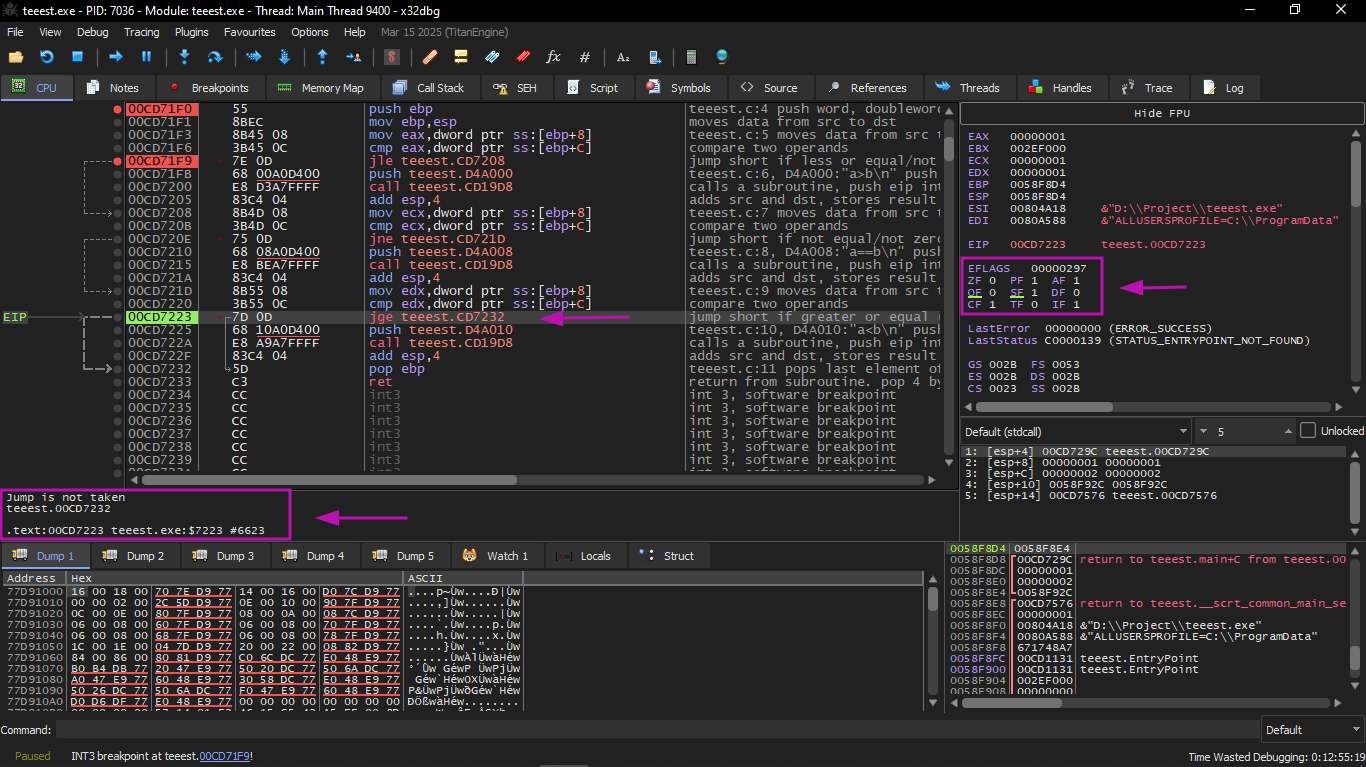
The third conditional jump: JGE
This jump will not be executed, because it needs:
SF=OF
And this is not met in our case.
x86 + MSVC + x32dbg
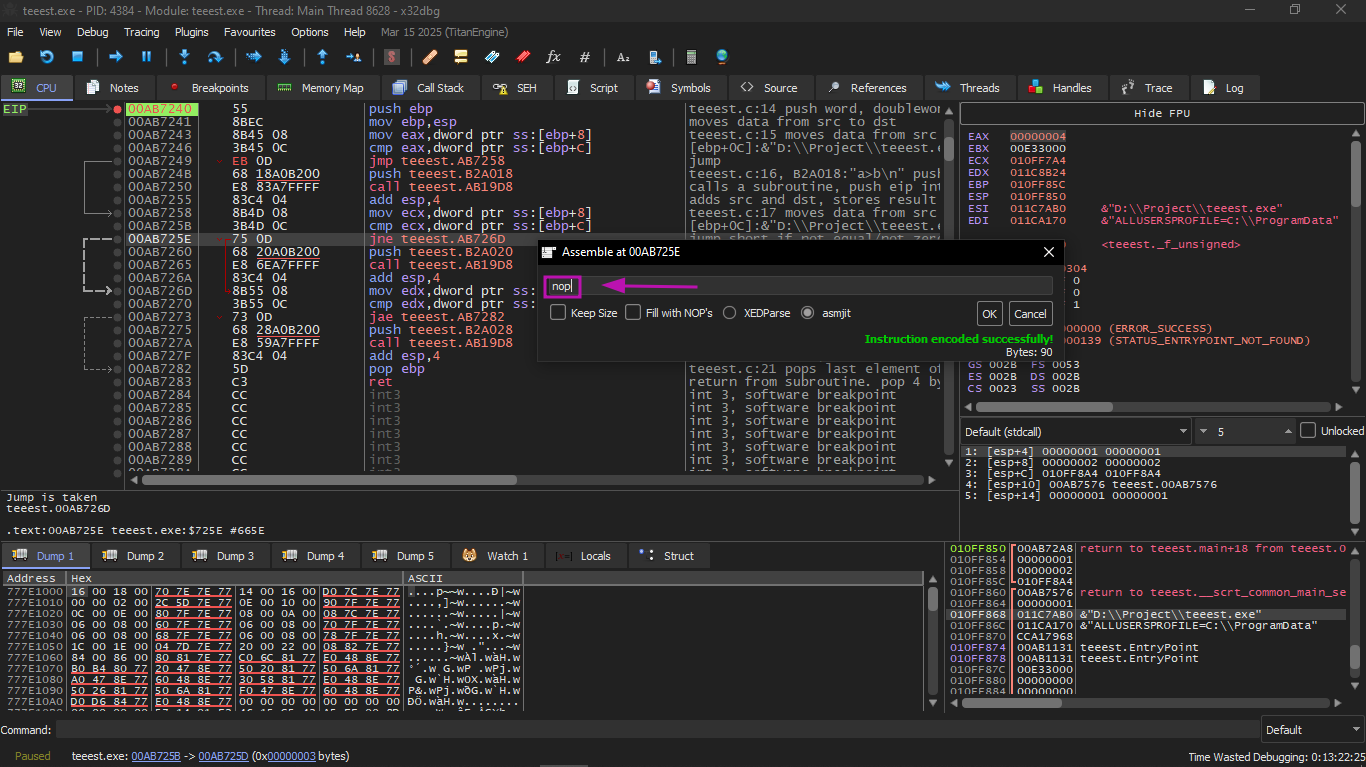
We can try to patch the executable file so that the f_unsigned() function always prints "a==b" regardless of the input values.
And for that we need to do 3 basic things:
- Make the first jump always execute
- Make the second jump never execute
- Make the third jump always execute
In this way, the execution path will always pass through the second printf(), and thus print "a==b"
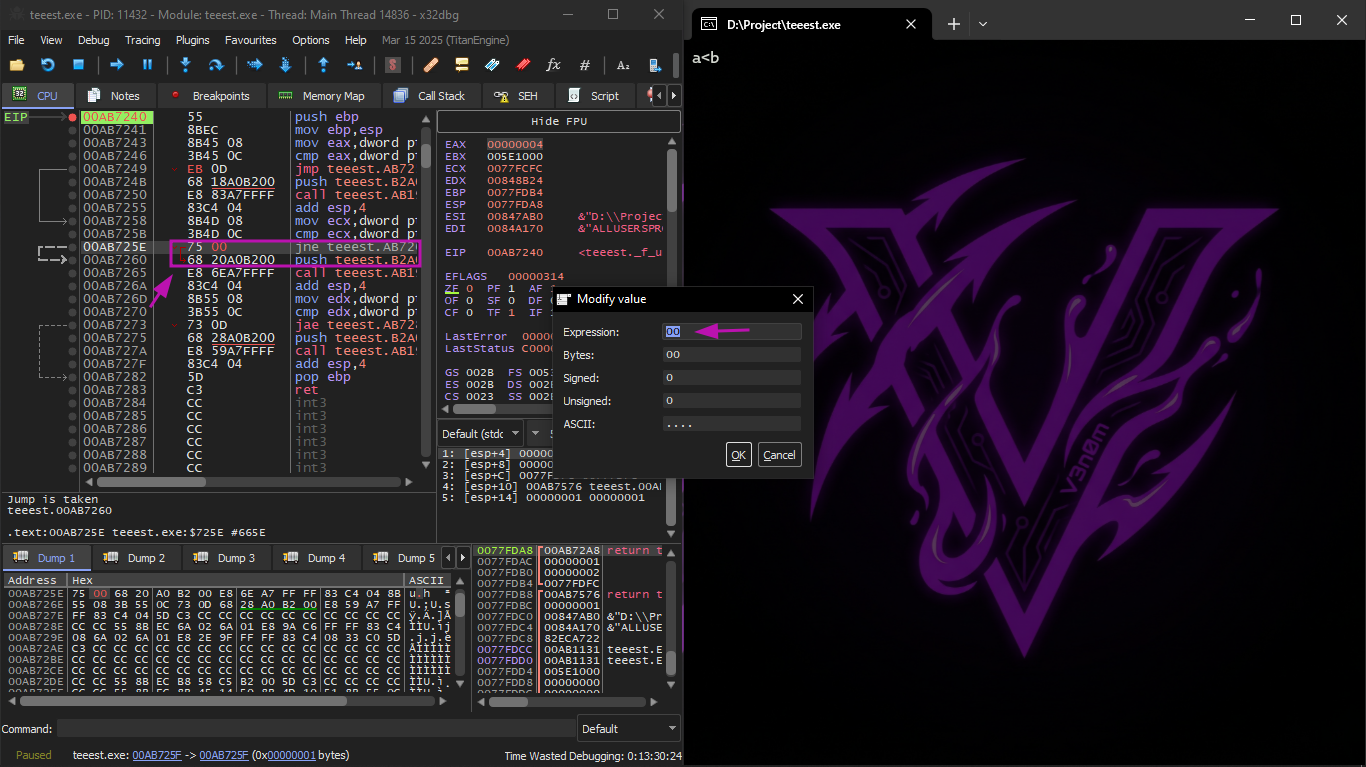
We will do it in two ways first we modify in the Assembly and the second way we modify in the HEX
* First jump make it normal JMP, and the jump offset remains as it is.
* Second jump may execute sometimes, but in all cases it will jump to the instruction right after it, because we will adjust the Assembly and make it NOP
* Third jump we will change it to JMP also, like the first, so it will always execute
And indeed it will come out like this
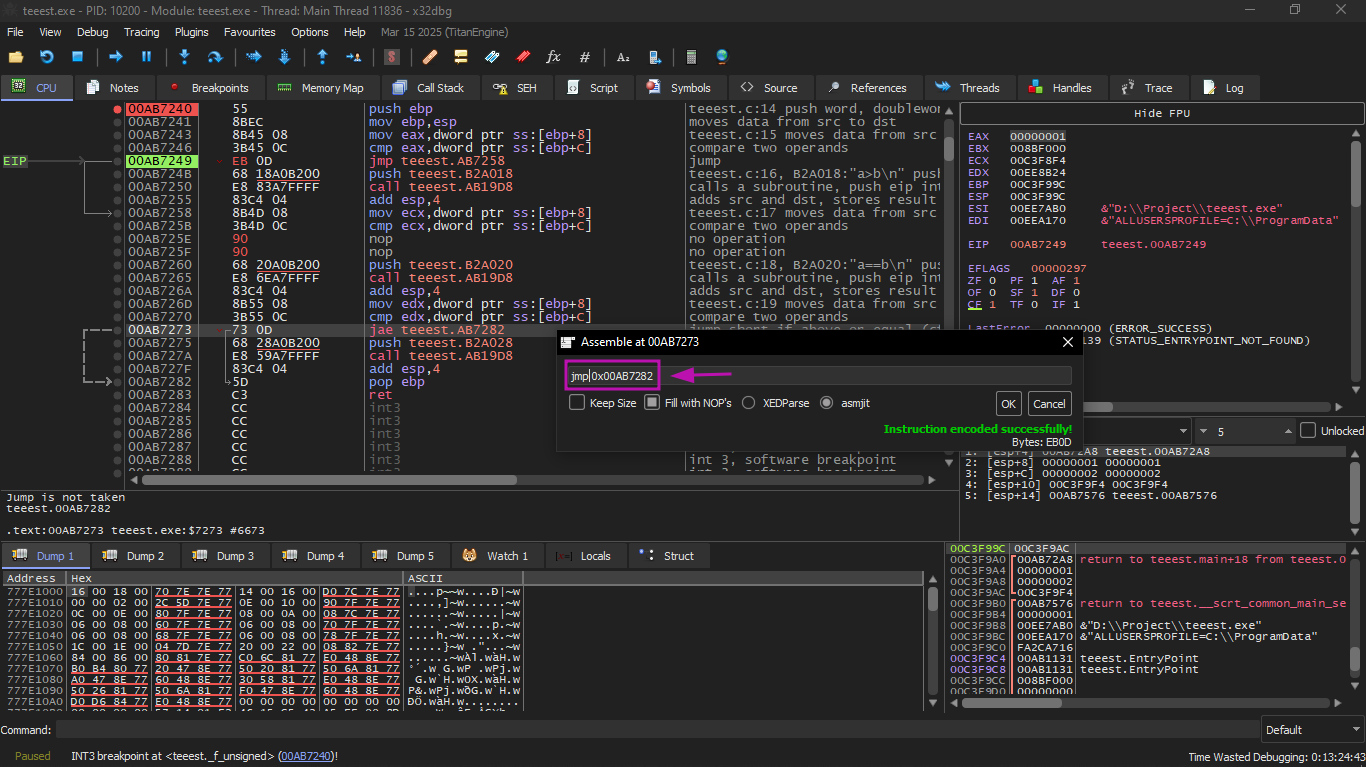
Now we come to the second way which is that we will do the same steps but we will go to the place of the instruction in each one :
* First jump we will start doing Follow in dump and go to HEX and change the value to EB which is jmp
* In the second jump we will change the Hex to zero which is also NOP
And here if you notice it jumped directly to the next one
And the last will be the same as the first and it will come out the same result in the end as the first
Non-optimizing GCC
GCC 4.4.1 version without optimization produces code very similar to this, but instead of printf() it uses puts()
Optimizing GCC
The question now is why execute the CMP instruction multiple times, as long as the flags come out with the same values after each execution?
MSVC may not be able to do this even with optimization, but GCC 4.8.1 with optimization can go a bit deeper:
f_signed:
mov eax, DWORD PTR [esp+8] ; load b into EAX
cmp DWORD PTR [esp+4], eax ; compare a with b
jg .L6 ; jump if a > b
je .L7 ; jump if a == b
jge .L1 ; jump if a >= b (impossible here)
mov DWORD PTR [esp+4], OFFSET FLAT:.LC2 ; "a<b" ; load address of "a<b\n"
jmp puts ; jump to puts
.L6:
mov DWORD PTR [esp+4], OFFSET FLAT:.LC0 ; "a>b" ; load address of "a>b\n"
jmp puts ; jump to puts
.L1:
rep ret ; return (dead code)
.L7:
mov DWORD PTR [esp+4], OFFSET FLAT:.LC1 ; "a==b" ; load address of "a==b\n"
jmp puts ; jump to puts
We also notice here that there is use of JMP puts instead of
CALL puts RETN
This type of trick will be explained later in the book this type of x86 code is relatively rare. It is clear that MSVC 2012, apparently, is not able to produce code in this form.
On the other hand, assembly programmers know very well that Jcc instructions
(conditional jumps) can be placed after each other (stacked).
And therefore, if you see stacking in this form somewhere, it is very likely that this code is hand-written and not the result of a compiler.
As for the f_unsigned() function it is not short nor very elegant:
f_unsigned:
push esi ; save ESI
push ebx ; save EBX
sub esp, 20 ; allocate stack space
mov esi, DWORD PTR [esp+32] ; load a into ESI
mov ebx, DWORD PTR [esp+36] ; load b into EBX
cmp esi, ebx ; compare a with b
ja .L13 ; jump if a > b (unsigned)
cmp esi, ebx ; compare again (could be removed)
je .L14 ; jump if a == b
.L10:
jb .L15 ; jump if a < b (unsigned)
add esp, 20 ; deallocate stack
pop ebx ; restore EBX
pop esi ; restore ESI
ret ; return
.L15:
mov DWORD PTR [esp+32], OFFSET FLAT:.LC2 ; "a<b" ; load address
add esp, 20 ; deallocate
pop ebx ; restore
pop esi ; restore
jmp puts ; jump to puts
.L13:
mov DWORD PTR [esp], OFFSET FLAT:.LC0 ; "a>b" ; load address
call puts ; call puts
cmp esi, ebx ; compare again
jne .L10 ; jump if not equal
.L14:
mov DWORD PTR [esp+32], OFFSET FLAT:.LC1 ; "a==b" ; load address
add esp, 20 ; deallocate
pop ebx ; restore
pop esi ; restore
jmp puts ; jump to puts
And with all this, we notice that there are only two CMP instructions instead of 3 like the previous examples.
This means that the optimization algorithms in GCC 4.8.1
Probably still not completely perfect.
ARM
ARM 32bit
Listing 1.115: Optimizing Keil 6/2013 (ARM mode)
.text:000000B8 EXPORT f_signed
.text:000000B8 f_signed ; CODE XREF: main+C
.text:000000B8 70 40 2D E9 STMFD SP!, {R4-R6,LR} ; save registers on stack
.text:000000BC 01 40 A0 E1 MOV R4, R1 ; move b to R4
.text:000000C0 04 00 50 E1 CMP R0, R4 ; compare a (R0) with b (R4)
.text:000000C4 00 50 A0 E1 MOV R5, R0 ; move a to R5
.text:000000C8 1A 0E 8F C2 ADRGT R0, aAB ; "a>b\n" ; load address if greater
.text:000000CC A1 18 00 CB BLGT __2printf ; call printf if greater
.text:000000D0 04 00 55 E1 CMP R5, R4 ; compare a with b again
.text:000000D4 67 0F 8F 02 ADREQ R0, aAB_0 ; "a==b\n" ; load address if equal
.text:000000D8 9E 18 00 0B BLEQ __2printf ; call printf if equal
.text:000000DC 04 00 55 E1 CMP R5, R4 ; compare again
.text:000000E0 70 80 BD A8 LDMGEFD SP!, {R4-R6,PC} ; restore and return if >=
.text:000000E4 70 40 BD E8 LDMFD SP!, {R4-R6,LR} ; restore registers (no return)
.text:000000E8 19 0E 8F E2 ADR R0, aAB_1 ; "a<b\n" ; load address
.text:000000EC 99 18 00 EA B __2printf ; unconditional branch to printf
The author said that many instructions in ARM Mode can be executed only if certain flags are set1
This style is used a lot in number comparison.
For example, the ADD instruction its real name internally is ADDAL and the AL means Always meaning execute always the predicates are encoded in the top 4 bits of the 32-bit ARM instruction (condition field).
Even the B instruction (unconditional jump) is in fact a conditional instruction, encoded like any other conditional jump,
But its condition is AL, meaning execute always regardless of the flags.
The ADRGT instruction works exactly like ADR, but is executed only if the CMP instruction before it found that the number is greater than the other (Greater Than).
Meaning ADRGT puts a pointer to the string "a>b\n" in register R0 while BLGT calls printf()
Thus any instruction ending with GT- is executed only if the value in R0 (which is a) is greater than the value in R4
(which is b )
After that we see ADREQ and BLEQ instructions.
These work like ADR and BL,
But are executed only if the two values were equal in the last comparison.
That's why there is another CMP before them,
Because calling printf() may have messed with the flags.
After that we see the LDMGEFD instruction.
This instruction works like LDMFD,
But is executed only when one of the values is greater or equal to the other (Greater or Equal).
The instruction:
LDMGEFD SP!, {R4-R6,PC}
This is considered function epilogue,
But it will be executed only if a >= b,
And then the function execution will end.
But if this condition is not met,
Meaning a < b,
Execution will continue to the next instruction:
LDMFD SP!, {R4-R6,LR}
This is also function epilogue,
But it returns LR not PC,
Thus it does not return from the function.
The last two instructions call printf()
With the text "a<b\n" as the only argument.
We have previously seen the issue of unconditional jump to printf()
Instead of returning from the function
In the part “printf() with several arguments”
The f_unsigned function is very similar to this,
But instead of:
* ADRGT
* BLGT
* LDMGEFD
It uses:
* ADRHI
* BLHI
* LDMCSFD
And these predicates:
* HI = Unsigned higher
* CS = Carry Set (greater or equal)
And these are counterparts to the predicates we saw before,
But for unsigned numbers.
There is nothing very new for us in the main() function:
Listing 1.116: main()
.text:00000128 EXPORT main
.text:00000128 main
.text:00000128 10 40 2D E9 STMFD SP!, {R4,LR} ; save registers
.text:0000012C 02 10 A0 E3 MOV R1, #2 ; load 2 into R1 (b)
.text:00000130 01 00 A0 E3 MOV R0, #1 ; load 1 into R0 (a)
.text:00000134 DF FF FF EB BL f_signed ; call f_signed
.text:00000138 02 10 A0 E3 MOV R1, #2 ; load 2
.text:0000013C 01 00 A0 E3 MOV R0, #1 ; load 1
.text:00000140 EA FF FF EB BL f_unsigned ; call f_unsigned
.text:00000144 00 00 A0 E3 MOV R0, #0 ; load return value 0
.text:00000148 10 80 BD E8 LDMFD SP!, {R4,PC} ; restore and return
And this is an example of how you can get rid of conditional jumps in ARM mode.
This feature is not present in x86,
Except for one instruction similar to it: CMOVcc.
This is like MOV,
But is executed only when certain flags are set,
And usually these flags come from CMP.
Optimizing Keil 6/2013 (Thumb mode)
Listing 1.117: Optimizing Keil 6/2013 (Thumb mode)
.text:00000072 f_signed ; CODE XREF: main+6
.text:00000072 70 B5 PUSH {R4-R6,LR} ; save registers
.text:00000074 0C 00 MOVS R4, R1 ; move b to R4
.text:00000076 05 00 MOVS R5, R0 ; move a to R5
.text:00000078 A0 42 CMP R0, R4 ; compare a with b
.text:0000007A 02 DD BLE loc_82 ; branch if <=
.text:0000007C A4 A0 ADR R0, aAB ; "a>b\n" ; load address
.text:0000007E 06 F0 B7 F8 BL __2printf ; call printf
.text:00000082
.text:00000082 loc_82 ; CODE XREF: f_signed+8
.text:00000082 A5 42 CMP R5, R4 ; compare again
.text:00000084 02 D1 BNE loc_8C ; branch if not equal
.text:00000086 A4 A0 ADR R0, aAB_0 ; "a==b\n" ; load address
.text:00000088 06 F0 B2 F8 BL __2printf ; call printf
.text:0000008C
.text:0000008C loc_8C ; CODE XREF: f_signed+12
.text:0000008C A5 42 CMP R5, R4 ; compare again
.text:0000008E 02 DA BGE locret_96 ; branch if >=
.text:00000090 A3 A0 ADR R0, aAB_1 ; "a<b\n" ; load address
.text:00000092 06 F0 AD F8 BL __2printf ; call printf
.text:00000096
.text:00000096 locret_96 ; CODE XREF: f_signed+1C
.text:00000096 70 BD POP {R4-R6,PC} ; restore and return
In Thumb mode,
Only B instructions can have condition codes added to them,
So Thumb code looks more normal.
* BLE = less or equal
* BNE = not equal
* BGE = greater or equal
The f_unsigned function is similar,
But uses other instructions with unsigned values:
* BLS (Unsigned lower or same)
* BCS (Carry Set – greater or equal)
ARM64: Optimizing GCC (Linaro) 4.9
Listing 1.118: f_signed()
f_signed:
; W0=a, W1=b
cmp w0, w1 ; compare a and b
bgt .L19 ; Branch if Greater Than (a>b)
beq .L20 ; Branch if Equal (a==b)
bge .L15 ; Branch if Greater or Equal (a>=b) (impossible here)
; a<b
adrp x0, .LC11 ; "a<b" ; load page address
add x0, x0, :lo12:.LC11 ; add offset
b puts ; branch to puts
.L19:
adrp x0, .LC9 ; "a>b" ; load page address
add x0, x0, :lo12:.LC9 ; add offset
b puts ; branch to puts
.L15: ; impossible to reach here
ret ; return
.L20:
adrp x0, .LC10 ; "a==b" ; load page address
add x0, x0, :lo12:.LC10 ; add offset
b puts ; branch to puts
Listing 1.119: f_unsigned()
f_unsigned:
stp x29, x30, [sp, -48]! ; save frame pointer and link register
; W0=a, W1=b
cmp w0, w1 ; compare a and b
add x29, sp, 0 ; set frame pointer
str x19, [sp,16] ; save X19
mov w19, w0 ; move a to W19
bhi .L25 ; branch if higher (unsigned a>b)
cmp w19, w1 ; compare again
beq .L26 ; branch if equal (a==b)
.L23:
bcc .L27 ; branch if carry clear (a<b unsigned)
; function epilogue (impossible to reach here)
ldr x19, [sp,16] ; restore X19
ldp x29, x30, [sp], 48 ; restore and deallocate
ret ; return
.L27:
ldr x19, [sp,16] ; restore X19
adrp x0, .LC11 ; "a<b" ; load page
ldp x29, x30, [sp], 48 ; restore
add x0, x0, :lo12:.LC11 ; add offset
b puts ; branch to puts
.L25:
adrp x0, .LC9 ; "a>b" ; load page
str x1, [x29,40] ; save b
add x0, x0, :lo12:.LC9 ; add offset
bl puts ; call puts
ldr x1, [x29,40] ; restore b
cmp w19, w1 ; compare
bne .L23 ; branch if not equal
.L26:
ldr x19, [sp,16] ; restore X19
adrp x0, .LC10 ; "a==b" ; load page
ldp x29, x30, [sp], 48 ; restore
add x0, x0, :lo12:.LC10 ; add offset
b puts ; branch to puts
The comments in the code are added by the author of the book himself.
What is striking here is that the compiler
Did not notice that some conditions are impossible to happen in the first place,
So there is dead code in several places,
Code that will never be executed.
MIPS
The author mentioned that one of the distinctive things in MIPS is that there are no flags. Apparently this is done to simplify data dependency analysis.
There are instructions similar to SETcc in x86: there is SLT (“Set on Less Than”: the signed version) and SLTU (the unsigned version).
These instructions put the value 1 in the destination register if the condition is met, or 0 if not.
After that the destination register is checked using BEQ (“Branch on Equal”) or BNE (“Branch on Not Equal”) and a jump may occur.
Meaning, this pair of instructions must be used in MIPS for comparison and branching.
We will start with the signed version of our function:
Listing 1.120: Non-optimizing GCC 4.4.5 (IDA)
.text:00000000 f_signed: # CODE XREF: main+18
.text:00000000
.text:00000000 var_10 = -0x10
.text:00000000 var_8 = -8
.text:00000000 var_4 = -4
.text:00000000 arg_0 = 0
.text:00000000 arg_4 = 4
.text:00000000
.text:00000000 addiu $sp, -0x20 ; allocate stack frame
.text:00000004 sw $ra, 0x20+var_4($sp) ; save return address
.text:00000008 sw $fp, 0x20+var_8($sp) ; save frame pointer
.text:0000000C move $fp, $sp ; set frame pointer
.text:00000010 la $gp, __gnu_local_gp ; load global pointer
.text:00000018 sw $gp, 0x20+var_10($sp) ; save global pointer
; save input values on stack
.text:0000001C sw $a0, 0x20+arg_0($fp) ; save a
.text:00000020 sw $a1, 0x20+arg_4($fp) ; save b
; reload them
.text:00000024 lw $v1, 0x20+arg_0($fp) ; load a into $v1
.text:00000028 lw $v0, 0x20+arg_4($fp) ; load b into $v0
.text:0000002C or $at, $zero ; NOP
; this is pseudoinstruction. actually "slt $v0,$v0,$v1"
.text:00000030 slt $v0, $v1 ; set $v0 to 1 if b < a (i.e. a > b)
; if condition not met, go to loc_5C
.text:00000034 beqz $v0, loc_5C ; branch if $v0 == 0
; print "a>b" and done
.text:00000038 or $at, $zero ; NOP
.text:0000003C lui $v0, (unk_230 >> 16) # "a>b"
.text:00000040 addiu $a0, $v0, (unk_230 & 0xFFFF) ; load address
.text:00000044 lw $v0, (puts & 0xFFFF)($gp) ; load puts address
.text:00000048 or $at, $zero ; NOP
.text:0000004C move $t9, $v0 ; move to $t9
.text:00000050 jalr $t9 ; call puts
.text:00000054 or $at, $zero ; NOP
.text:00000058 lw $gp, 0x20+var_10($fp) ; restore gp
.text:0000005C loc_5C:
.text:0000005C lw $v1, 0x20+arg_0($fp) ; reload a
.text:00000060 lw $v0, 0x20+arg_4($fp) ; reload b
.text:00000064 or $at, $zero ; NOP
; if a!=b go loc_90
.text:00000068 bne $v1, $v0, loc_90 ; branch if not equal
.text:0000006C or $at, $zero ; NOP
; condition met, print "a==b"
.text:00000070 lui $v0, (aAB >> 16) # "a==b"
.text:00000074 addiu $a0, $v0, (aAB & 0xFFFF) ; load address
.text:00000078 lw $v0, (puts & 0xFFFF)($gp) ; load puts
.text:0000007C or $at, $zero ; NOP
.text:00000080 move $t9, $v0 ; move to $t9
.text:00000084 jalr $t9 ; call puts
.text:00000088 or $at, $zero ; NOP
.text:0000008C lw $gp, 0x20+var_10($fp) ; restore gp
.text:00000090 loc_90:
.text:00000090 lw $v1, 0x20+arg_0($fp) ; reload a
.text:00000094 lw $v0, 0x20+arg_4($fp) ; reload b
.text:00000098 or $at, $zero ; NOP
; if a<b, set $v0=1
.text:0000009C slt $v0, $v1, $v0 ; set if a < b
.text:000000A0 beqz $v0, loc_C8 ; if not met, go loc_C8
.text:000000A4 or $at, $zero ; NOP
; condition met, print "a<b"
.text:000000A8 lui $v0, (aAB_0 >> 16) # "a<b"
.text:000000AC addiu $a0, $v0, (aAB_0 & 0xFFFF) ; load address
.text:000000B0 lw $v0, (puts & 0xFFFF)($gp) ; load puts
.text:000000B4 or $at, $zero ; NOP
.text:000000B8 move $t9, $v0 ; move to $t9
.text:000000BC jalr $t9 ; call puts
.text:000000C0 or $at, $zero ; NOP
.text:000000C4 lw $gp, 0x20+var_10($fp) ; restore gp
.text:000000C8 loc_C8:
.text:000000C8 move $sp, $fp ; restore stack pointer
.text:000000CC lw $ra, 0x20+var_4($sp) ; restore return address
.text:000000D0 lw $fp, 0x20+var_8($sp) ; restore frame pointer
.text:000000D4 addiu $sp, 0x20 ; deallocate stack
.text:000000D8 jr $ra ; return
.text:000000DC or $at, $zero ; NOP
Notes:
* SLT REG0, REG0, REG1 abbreviated by IDA to SLT REG0, REG1.
* There is BEQZ pseudo instruction (“Branch if Equal to Zero”), which is actually BEQ REG, $ZERO, LABEL.
* The unsigned version is very similar, but instead of SLT it uses SLTU:
.text:000000E0 f_unsigned:
.text:000000E0 addiu $sp, -0x20 ; allocate stack
.text:000000E4 sw $ra, 0x20+var_4($sp) ; save RA
.text:000000E8 sw $fp, 0x20+var_8($sp) ; save FP
.text:000000EC move $fp, $sp ; set FP
.text:000000F0 la $gp, __gnu_local_gp ; load GP
.text:000000F8 sw $gp, 0x20+var_10($sp) ; save GP
.text:000000FC sw $a0, 0x20+arg_0($fp) ; save a
.text:00000100 sw $a1, 0x20+arg_4($fp) ; save b
.text:00000104 lw $v1, 0x20+arg_0($fp) ; load a
.text:00000108 lw $v0, 0x20+arg_4($fp) ; load b
.text:0000010C or $at, $zero ; NOP
.text:00000110 sltu $v0, $v1 ; set $v0 to 1 if a > b (unsigned)
.text:00000114 beqz $v0, loc_13C ; branch if not
.text:00000118 or $at, $zero ; NOP
; print "a>b"
.text:0000011C lui $v0, (unk_230 >> 16)
.text:00000120 addiu $a0, $v0, (unk_230 & 0xFFFF)
.text:00000124 lw $v0, (puts & 0xFFFF)($gp)
.text:00000128 or $at, $zero ; NOP
.text:0000012C move $t9, $v0
.text:00000130 jalr $t9
.text:00000134 or $at, $zero ; NOP
.text:00000138 lw $gp, 0x20+var_10($fp)
.text:0000013C loc_13C:
.text:0000013C lw $v1, 0x20+arg_0($fp)
.text:00000140 lw $v0, 0x20+arg_4($fp)
.text:00000144 or $at, $zero ; NOP
.text:00000148 bne $v1, $v0, loc_170 ; branch if a != b
.text:0000014C or $at, $zero ; NOP
; print "a==b"
.text:00000150 lui $v0, (aAB >> 16)
.text:00000154 addiu $a0, $v0, (aAB & 0xFFFF)
.text:00000158 lw $v0, (puts & 0xFFFF)($gp)
.text:0000015C or $at, $zero ; NOP
.text:00000160 move $t9, $v0
.text:00000164 jalr $t9
.text:00000168 or $at, $zero ; NOP
.text:0000016C lw $gp, 0x20+var_10($fp)
.text:00000170 loc_170:
.text:00000170 lw $v1, 0x20+arg_0($fp)
.text:00000174 lw $v0, 0x20+arg_4($fp)
.text:00000178 or $at, $zero ; NOP
.text:0000017C sltu $v0, $v1, $v0 ; set if a < b (unsigned)
.text:00000180 beqz $v0, loc_1A8 ; branch if not
.text:00000184 or $at, $zero ; NOP
; print "a<b"
.text:00000188 lui $v0, (aAB_0 >> 16)
.text:0000018C addiu $a0, $v0, (aAB_0 & 0xFFFF)
.text:00000190 lw $v0, (puts & 0xFFFF)($gp)
.text:00000194 or $at, $zero ; NOP
.text:00000198 move $t9, $v0
.text:0000019C jalr $t9
.text:000001A0 or $at, $zero ; NOP
.text:000001A4 lw $gp, 0x20+var_10($fp)
.text:000001A8 loc_1A8:
.text:000001A8 move $sp, $fp ; restore SP
.text:000001AC lw $ra, 0x20+var_4($sp) ; restore RA
.text:000001B0 lw $fp, 0x20+var_8($sp) ; restore FP
.text:000001B4 addiu $sp, 0x20 ; deallocate
.text:000001B8 jr $ra ; return
.text:000001BC or $at, $zero ; NOP
1.18.2 Calculating absolute value
A simple function:
int my_abs(int i) // define absolute value function
{
if (i < 0) // check if input is negative
return -i; // return negated value
else
return i; // return original value
};
MSVC optimization
The code is usually generated in this form:
Listing 1.122: Optimizing MSVC 2012 x64
i$ = 8
my_abs PROC
; ECX = input
test ecx, ecx ; test sign of value
jns SHORT $LN2@my_abs ; skip NEG if sign positive
neg ecx ; negate value if negative
$LN2@my_abs:
mov eax, ecx ; prepare result in EAX
ret 0 ; return
my_abs ENDP
GCC 4.9 does almost the same thing.
Keil optimization 6/2013: Thumb mode
Listing 1.123: Optimizing Keil 6/2013: Thumb mode
my_abs PROC
CMP r0, #0 ; is input zero or greater?
BGE |L0.6| ; skip RSBS if value >= 0
RSBS r0, r0, #0 ; subtract value from zero (negate)
|L0.6|
BX lr ; return
ENDP
ARM has no sign reversal instruction, so Keil compiler uses “Reverse Subtract”
Which simply subtracts in reverse.
Keil optimization 6/2013: ARM mode
You can add a condition to execute some instructions in ARM mode, and this is what Keil compiler does:
Listing 1.124: Optimizing Keil 6/2013: ARM mode
my_abs PROC
CMP r0, #0 ; compare with zero
RSBLT r0, r0, #0 ; execute Reverse Subtract if value < 0
BX lr ; return
ENDP
Now there is no conditional jump and this is good
GCC 4.9 non-optimized (ARM64)
ARM64 has NEG instruction for sign reversal:
Listing 1.125: Optimizing GCC 4.9 (ARM64)
my_abs:
sub sp, sp, #16 ; allocate stack
str w0, [sp, 12] ; save input
ldr w0, [sp, 12] ; load input
cmp w0, wzr ; compare with zero (WZR always zero)
bge .L2 ; skip if >=0
ldr w0, [sp, 12] ; load input
neg w0, w0 ; negate value
b .L3
.L2:
ldr w0, [sp, 12] ; load original
.L3:
add sp, sp, 16 ; deallocate
ret ; return
MIPS
Listing 1.126: Optimizing GCC 4.4.5 (IDA)
my_abs:
bltz $a0, locret_10 ; branch if $a0 < 0
move $v0, $a0 ; return original value in $v0
jr $ra ; return
or $at, $zero ; branch delay slot, NOP
locret_10:
negu $v0, $a0 ; negate value ($v0 = 0 - $a0)
jr $ra ; return
We saw a new instruction: BLTZ (“branch if less than zero”).
Also there is pseudo instruction NEGU, which simply subtracts from zero.
The “U” suffix in SUBU and NEGU means no exception will be raised if integer Overflow occurs.
You can also make a version of the code without jumps. We will talk about that later