1.26 Arrays
Let's first define what an Array is: it is a group of variables stored next to each other in memory, all of the same type.
Here is a simple example:
#include <stdio.h> // include standard I/O header
int main() {
int a[20]; // declare an array of 20 integers (20 × 4 = 80 bytes on stack)
int i; // loop counter
for (i = 0; i < 20; i++) // iterate from 0 to 19
a[i] = i * 2; // fill each element with index × 2
for (i = 0; i < 20; i++) // iterate again to print
printf("a[%d]=%d\n", i, a[i]); // print index and value
return 0; // return 0 to indicate successful termination
}
x86
MSVC
Let's compile it and it will look like this:
_TEXT SEGMENT
_i$ = -84 ; variable i (4 bytes) offset on stack
_a$ = -80 ; array a (80 bytes) offset on stack
_main PROC
push ebp ; save base pointer
mov ebp, esp ; set up stack frame
sub esp, 84 ; allocate 84 bytes: 80 for array + 4 for i
; === First loop: fill the array ===
mov DWORD PTR _i$[ebp], 0 ; i = 0
jmp SHORT $LN6@main ; jump to loop condition check
$LN5@main: ; loop increment label
mov eax, DWORD PTR _i$[ebp] ; load i into EAX
add eax, 1 ; EAX = i + 1
mov DWORD PTR _i$[ebp], eax ; i = i + 1
$LN6@main: ; loop condition label
cmp DWORD PTR _i$[ebp], 20 ; compare i with 20
jge SHORT $LN4@main ; if i >= 20, exit loop
mov ecx, DWORD PTR _i$[ebp] ; load i into ECX
shl ecx, 1 ; ECX = i * 2 (left shift by 1 bit = multiply by 2)
mov edx, DWORD PTR _i$[ebp] ; load i into EDX (used as index)
mov DWORD PTR _a$[ebp + edx*4], ecx ; a[i] = i*2 (address = base + i*4)
jmp SHORT $LN5@main ; jump back to increment
$LN4@main: ; after first loop
; === Second loop: print the array ===
mov DWORD PTR _i$[ebp], 0 ; i = 0
jmp SHORT $LN3@main ; jump to condition check
$LN2@main: ; loop increment label
mov eax, DWORD PTR _i$[ebp]
add eax, 1
mov DWORD PTR _i$[ebp], eax ; i = i + 1
$LN3@main: ; loop condition label
cmp DWORD PTR _i$[ebp], 20 ; compare i with 20
jge SHORT $LN1@main ; if i >= 20, exit loop
mov ecx, DWORD PTR _i$[ebp] ; load i as index
mov edx, DWORD PTR _a$[ebp + ecx*4] ; load a[i] into EDX
push edx ; push a[i] as third argument to printf
mov eax, DWORD PTR _i$[ebp] ; load i
push eax ; push i as second argument to printf
push OFFSET $SG2463 ; push format string "a[%d]=%d\n"
call _printf ; call printf
add esp, 12 ; clean up stack (3 arguments × 4 bytes)
jmp SHORT $LN2@main ; jump back to increment
$LN1@main: ; after second loop
xor eax, eax ; return value = 0
mov esp, ebp ; restore stack pointer
pop ebp ; restore base pointer
ret 0 ; return
_main ENDP
Nothing very strange, just two loops: the first loop fills the array (multiplying each element by 2), and the second loop prints the elements. But let's analyze the Assembly together a bit more for better understanding.
Imagine you have 20 drawers in a cabinet, all next to each other, and each drawer holds one number of type int. Therefore each drawer takes 4 bytes (because we said before that int in 32-bit takes 4 bytes), meaning the entire array takes 20 × 4 = 80 contiguous bytes.
Let's start with the instruction sub esp, 84 which allocates 84 bytes on the stack. Why 84 and not 80? In short, there are 4 extra bytes for the variable i.
Now let's go through the first loop — filling the array:
* mov _i$, 0 — as we know, start with i = 0
* cmp _i$, 20 — if i is greater than or equal to 20, exit the loop
* shl ecx, 1 — the fastest way to multiply i × 2 (instead of a regular multiply, a left shift by 1 bit = ×2)
* calculating the address of a[i]: mov DWORD PTR _a$[ebp + edx*4], ecx
An important question — why did the compiler use shl instead of imul? Because it is safer on the stack (no overflow if the array is small).
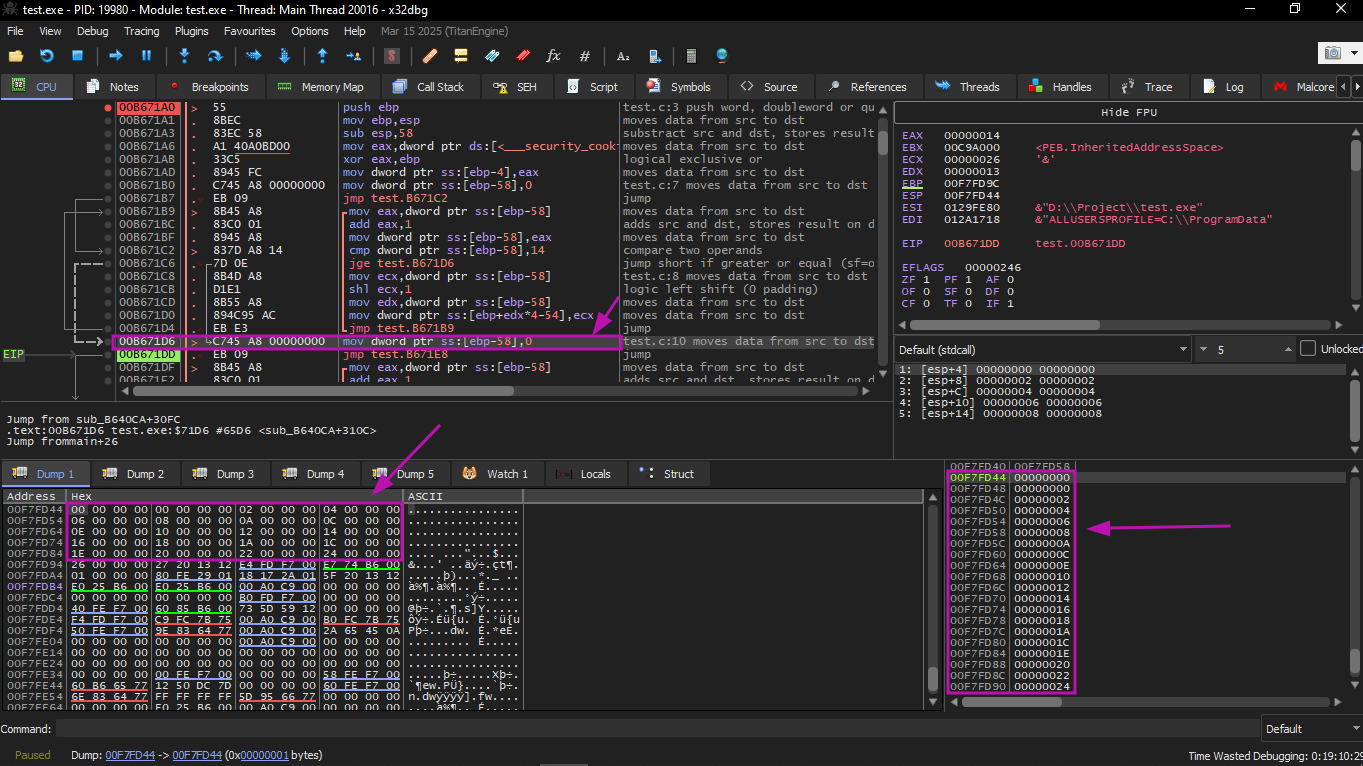
Let's try this example in x32dbg. We can see how the array is being filled: each element is a 32-bit int word and its value is the index multiplied by 2.
Since this array lives on the stack, we can see all 20 of its elements there.
GCC
This is what GCC produced:
main proc near
; DATA XREF: _start+17
var_70 = dword ptr -70h ; stack slot used for printf arg (value)
var_6C = dword ptr -6Ch ; stack slot used for printf arg (index)
var_68 = dword ptr -68h ; stack slot used for printf arg (format string pointer)
i_2 = dword ptr -54h ; array a starts here (20 ints = 80 bytes)
i = dword ptr -4 ; loop counter i
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h ; align stack to 16 bytes
sub esp, 70h ; allocate 112 bytes on stack
mov [esp+70h+i], 0 ; i = 0
jmp short loc_804840A ; jump to loop condition
loc_80483F7: ; loop body
mov eax, [esp+70h+i] ; load i into EAX (used as array index)
mov edx, [esp+70h+i] ; load i into EDX
add edx, edx ; EDX = i * 2 (add to itself = multiply by 2)
mov [esp+eax*4+70h+i_2], edx ; a[i] = i*2 (address = array_base + i*4)
add [esp+70h+i], 1 ; i++
loc_804840A: ; loop condition
cmp [esp+70h+i], 13h ; compare i with 19 (0x13)
jle short loc_80483F7 ; if i <= 19, continue loop
mov [esp+70h+i], 0 ; i = 0 (reset for second loop)
jmp short loc_8048441 ; jump to second loop condition
loc_804841B: ; second loop body
mov eax, [esp+70h+i] ; load i as index
mov edx, [esp+eax*4+70h+i_2]; load a[i] into EDX
mov eax, offset aADD ; load address of format string "a[%d]=%d\n"
mov [esp+70h+var_68], edx ; push a[i] as third arg on stack
mov edx, [esp+70h+i] ; load i
mov [esp+70h+var_6C], edx ; push i as second arg on stack
mov [esp+70h+var_70], eax ; push format string as first arg on stack
call _printf ; call printf
add [esp+70h+i], 1 ; i++
loc_8048441: ; second loop condition
cmp [esp+70h+i], 13h ; compare i with 19
jle short loc_804841B ; if i <= 19, continue loop
mov eax, 0 ; return value = 0
leave ; restore stack frame
retn ; return
main endp
By the way, the variable a is of type int (a pointer to int). You can pass a pointer to an array to another function, but it is more accurate to say "a pointer to the first element of the array is being passed" (and the rest of the addresses are calculated in a straightforward way). If you do indexing on this pointer like a[idx], idx is just added to the pointer and the element at that address is returned.
An interesting example: a string like "string" is an array of characters of type const char[]. You can do indexing on this pointer too. That is why it is possible to write "string"[i] and that is a completely valid expression in C/C++!
ARM
Non-optimizing Keil 6/2013 (ARM mode)
EXPORT _main
_main
STMFD SP!, {R4,LR} ; save R4 and link register on stack
SUB SP, SP, #0x50 ; allocate 80 bytes (0x50) for 20 int array
; First loop: fill the array
MOV R4, #0 ; i = 0 (R4 is the loop counter)
B loc_4A0 ; jump to loop condition
loc_494: ; loop body
MOV R0, R4,LSL#1 ; R0 = R4 * 2 (left shift by 1 = multiply by 2)
STR R0, [SP,R4,LSL#2] ; store R0 at address SP + R4*4 (a[i] = i*2)
ADD R4, R4, #1 ; i++
loc_4A0: ; loop condition
CMP R4, #20 ; compare i with 20
BLT loc_494 ; if i < 20, continue loop
; Second loop: print the array
MOV R4, #0 ; i = 0 (reset counter)
B loc_4C4 ; jump to loop condition
loc_4B0: ; loop body
LDR R2, [SP,R4,LSL#2] ; R2 = a[i] (load from SP + i*4)
MOV R1, R4 ; R1 = i (second argument to printf)
ADR R0, aADD ; R0 = address of format string "a[%d]=%d\n"
BL __2printf ; call printf(format, i, a[i])
ADD R4, R4, #1 ; i++
loc_4C4: ; loop condition
CMP R4, #20 ; compare i with 20
BLT loc_4B0 ; if i < 20, continue loop
MOV R0, #0 ; return value = 0
ADD SP, SP, #0x50 ; deallocate array space
LDMFD SP!, {R4,PC} ; restore R4 and return
The int type takes 32 bits (4 bytes), so 20 elements need 80 bytes (0x50). The SUB SP, SP, #0x50 instruction at the beginning of the function allocates exactly that space.
In both loops, the counter i lives in R4. The number written into the array = i*2, and this is translated into MOV R0, R4,LSL#1 (left shift by 1 bit = multiply by 2). STR R0, [SP,R4,LSL#2] writes to the array. The element address = SP (start of array) + R4*4 (because each element is 4 bytes).
Optimizing Keil 6/2013 (Thumb mode)
_main
PUSH {R4,R5,LR} ; save R4, R5 and link register
SUB SP, SP, #0x54 ; allocate 84 bytes: 80 for array + 4 extra (alignment)
MOVS R0, #0 ; i = 0
MOV R5, SP ; R5 = base address of the array
loc_1CE: ; first loop body
LSLS R1, R0, #1 ; R1 = i * 2 (left shift = multiply by 2)
LSLS R2, R0, #2 ; R2 = i * 4 (byte offset into array)
ADDS R0, R0, #1 ; i++
CMP R0, #20 ; compare i with 20
STR R1, [R5,R2] ; store i*2 at address (R5 + i*4) → a[i] = i*2
BLT loc_1CE ; if i < 20, continue loop
MOVS R4, #0 ; i = 0 (reset for second loop)
loc_1DC: ; second loop body
LSLS R0, R4, #2 ; R0 = i * 4 (byte offset)
LDR R2, [R5,R0] ; R2 = a[i] (load from base + i*4)
MOVS R1, R4 ; R1 = i (second argument to printf)
ADR R0, aADD ; R0 = address of format string "a[%d]=%d\n"
BL __2printf ; call printf(format, i, a[i])
ADDS R4, R4, #1 ; i++
CMP R4, #20 ; compare i with 20
BLT loc_1DC ; if i < 20, continue loop
MOVS R0, #0 ; return value = 0
ADD SP, SP, #0x54 ; deallocate stack space
POP {R4,R5,PC} ; restore and return
The Thumb code is similar to the previous one but with dedicated shift instructions (LSLS). The compiler allocated 84 bytes instead of 80, the last 4 bytes are unused.
Non-optimizing GCC 4.9.1 (ARM64)
Listing 1.230
.LC0:
.string "a[%d]=%d\n" ; format string for printf
main:
stp x29, x30, [sp, -112]! ; save frame pointer and link register, allocate 112 bytes
add x29, sp, 0 ; set frame pointer
str wzr, [x29,108] ; i = 0 (wzr is always zero)
b .L2 ; jump to loop condition
.L3: ; first loop body
ldr w0, [x29,108] ; load i into W0
lsl w2, w0, 1 ; W2 = i * 2 (left shift by 1)
add x0, x29, 24 ; X0 = base address of array a (x29 + 24)
ldrsw x1, [x29,108] ; load i as 64-bit signed value into X1
str w2, [x0,x1,lsl 2] ; a[i] = i*2 (store at base + i*4)
ldr w0, [x29,108] ; load i
add w0, w0, 1 ; W0 = i + 1
str w0, [x29,108] ; i++
.L2: ; first loop condition
ldr w0, [x29,108] ; load i
cmp w0, 19 ; compare i with 19
ble .L3 ; if i <= 19, continue loop
str wzr, [x29,108] ; i = 0 (reset for second loop)
b .L4 ; jump to second loop condition
.L5: ; second loop body
add x0, x29, 24 ; X0 = base address of array
ldrsw x1, [x29,108] ; load i as 64-bit index
ldr w2, [x0,x1,lsl 2] ; W2 = a[i] (load from base + i*4)
adrp x0, .LC0 ; load page address of format string
add x0, x0, :lo12:.LC0 ; add page offset to get full address
ldr w1, [x29,108] ; W1 = i (second argument to printf)
bl printf ; call printf(format, i, a[i])
ldr w0, [x29,108] ; load i
add w0, w0, 1 ; W0 = i + 1
str w0, [x29,108] ; i++
.L4: ; second loop condition
ldr w0, [x29,108] ; load i
cmp w0, 19 ; compare i with 19
ble .L5 ; if i <= 19, continue loop
mov w0, 0 ; return value = 0
ldp x29, x30, [sp], 112 ; restore frame pointer and link register
ret ; return
MIPS
The function uses many (S-registers) which must be preserved, so their values are saved at the beginning of the function (prologue) and restored at the end (epilogue).
Listing 1.231: Optimizing GCC 4.4.5 (IDA)
main:
; function prologue: save registers and set up stack
lui $gp, (__gnu_local_gp >> 16) ; load upper 16 bits of global pointer
addiu $sp, -0x80 ; allocate 128 bytes on stack
la $gp, (__gnu_local_gp & 0xFFFF) ; load lower 16 bits of global pointer
sw $ra, 0x80+var_4($sp) ; save return address
sw $s3, 0x80+var_8($sp) ; save S3
; ... (save more S-registers)
addiu $s1, $sp, 0x80+var_68 ; S1 = base address of array a on stack
move $v1, $s1 ; V1 = pointer to current array element
move $v0, $zero ; V0 = 0 (value to write, starts at 0)
li $a0, 0x28 ; A0 = 40 (loop stops when V0 == 40, i.e. i*2 reaches 40)
loc_34: ; first loop body
sw $v0, 0($v1) ; store current value (i*2) into current element
addiu $v0, 2 ; V0 += 2 (next value = (i+1)*2)
bne $v0, $a0, loc_34 ; if V0 != 40, continue loop
addiu $v1, 4 ; delay slot: advance pointer by 4 bytes (next element)
la $s3, $LC0 ; S3 = address of format string "a[%d]=%d\n"
move $s0, $zero ; S0 = 0 (i counter for second loop)
li $s2, 0x14 ; S2 = 20 (loop limit)
loc_54: ; second loop body
lw $t9, (printf & 0xFFFF)($gp) ; load address of printf from GOT
lw $a2, 0($s1) ; A2 = a[i] (load current element)
move $a1, $s0 ; A1 = i (second argument)
move $a0, $s3 ; A0 = format string (first argument)
jalr $t9 ; call printf
addiu $s0, 1 ; delay slot: i++
lw $gp, 0x80+var_70($sp) ; restore global pointer after call
bne $s0, $s2, loc_54 ; if i != 20, continue loop
addiu $s1, 4 ; delay slot: advance array pointer by 4 bytes
; epilogue: restore registers and return
jr $ra ; return
addiu $sp, 0x80 ; delay slot: deallocate stack
$LC0: .ascii "a[%d]=%d\n" ; format string constant
An interesting thing: in both loops, the first loop does not need i at all! It only needs the value (i*2) which increases by +2 each time, and the memory address which increases by +4.
So we see two variables: one in $v0 that increases by +2, and another in $v1 that increases by +4.
The second loop is the one that calls printf and tells the user the value of i, which is why there is a variable that increases by +1 (in $s0) and an address that increases by +4 (in $s1).
This reminds us of loop optimizations that we talked about before. The goal is to completely eliminate multiplication operations.
1.26.2 Buffer overflow
Reading outside array bounds
When dealing with an array like array[index], if you look carefully at the code that the compiler generates, you will notice there is no bounds checking at all — meaning nothing checks whether the index is less than 20 or not.
What if the index becomes 20 or greater? This is exactly one of the most criticized things about C/C++. Here is code that compiles and runs just fine:
#include <stdio.h> // include standard I/O header
int main() {
int a[20]; // array of 20 integers
int i; // loop counter
for (i = 0; i < 20; i++) // fill array with i*2
a[i] = i * 2;
printf("a[20]=%d\n", a[20]); // read one element BEYOND the array bounds (index 20 is invalid)
return 0;
}
Compile result (Non-optimizing MSVC 2008)
Listing 1.232
$SG2474 DB 'a[20]=%d', 0aH, 00H ; format string with newline and null terminator
_i$ = -84 ; size = 4 ; variable i offset on stack
a$ = -80 ; size = 80 ; array a offset on stack (20 × 4 bytes)
_main PROC
push ebp ; save base pointer
mov ebp, esp ; set up stack frame
sub esp, 84 ; allocate 84 bytes: 80 for array + 4 for i
mov DWORD PTR _i$[ebp], 0 ; i = 0
jmp SHORT $LN3@main ; jump to loop condition
$LN2@main: ; loop increment
mov eax, DWORD PTR _i$[ebp] ; load i
add eax, 1 ; i + 1
mov DWORD PTR _i$[ebp], eax ; i++
$LN3@main: ; loop condition
cmp DWORD PTR _i$[ebp], 20 ; compare i with 20
jge SHORT $LN1@main ; if i >= 20, exit loop
mov ecx, DWORD PTR _i$[ebp] ; load i into ECX
shl ecx, 1 ; ECX = i * 2
mov edx, DWORD PTR _i$[ebp] ; load i as index
mov DWORD PTR _a$[ebp+edx*4], ecx ; a[i] = i*2
jmp SHORT $LN2@main ; loop back
$LN1@main:
mov eax, DWORD PTR _a$[ebp+80] ; read from a[20] — 80 bytes past start of array (OUT OF BOUNDS!)
push eax ; push value as argument to printf
push OFFSET $SG2474 ; push format string "a[20]=%d\n"
call DWORD PTR __imp__printf ; call printf
add esp, 8 ; clean up stack (2 arguments)
xor eax, eax ; return value = 0
mov esp, ebp ; restore stack pointer
pop ebp ; restore base pointer
ret 0 ; return
_main ENDP
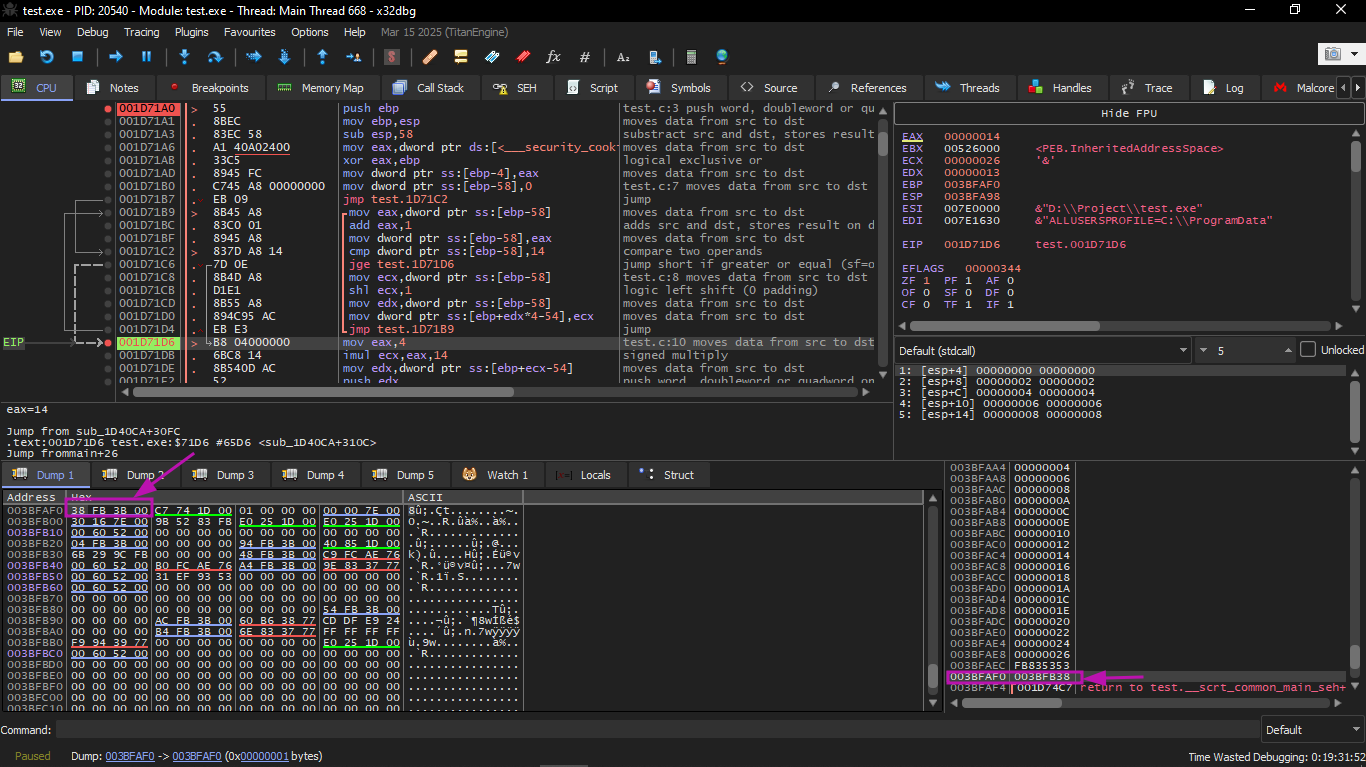
The result that came out was a[20]=1638280, and it is obviously clear that this number is not an array value at all — it is a value that was sitting on the stack 80 bytes past the first element of a[].
Let's try to figure out where that value came from. We will do the same example on x32dbg and look at the value that is sitting exactly after the last element of the array.
What is this?
From the look of the stack, this is the saved value of register EBP (which was saved at the beginning of the function).
Let's follow further and see how this value comes back:
Indeed, how could it be otherwise? The compiler could generate extra code to check that the index is always within the array bounds (like what happens in higher-level languages), but that would make the code slower.
Writing beyond array bounds
Alright, we read values from the stack illegally, but what if we could write something into it?
Here is what happens:
#include <stdio.h> // include standard I/O header
int main() {
int a[20]; // array of only 20 integers
int i;
for (i = 0; i < 30; i++) // loop goes to 30 — writes 10 elements BEYOND array bounds!
a[i] = i; // overwrites stack memory past the array
return 0;
}
MSVC
Here is what we found:
_i$ = -84 ; variable i offset on stack
a$ = -80 ; array a offset on stack
_main PROC
push ebp ; save base pointer
mov ebp, esp ; set up stack frame
sub esp, 84 ; allocate 84 bytes on stack
mov DWORD PTR _i$[ebp], 0 ; i = 0
jmp SHORT $LN3@main ; jump to loop condition
$LN2@main: ; loop increment
mov eax, DWORD PTR _i$[ebp] ; load i
add eax, 1 ; i + 1
mov DWORD PTR _i$[ebp], eax ; i++
$LN3@main: ; loop condition
cmp DWORD PTR _i$[ebp], 30 ; compare i with 30 (NOT 20 — loop goes beyond array!)
jge SHORT $LN1@main ; if i >= 30, exit loop
mov ecx, DWORD PTR _i$[ebp] ; load i as index
mov edx, DWORD PTR _i$[ebp] ; load i as value (redundant load — could be optimized)
mov DWORD PTR _a$[ebp+ecx*4], edx ; a[i] = i (writes past end of array for i >= 20!)
jmp SHORT $LN2@main ; loop back
$LN1@main:
xor eax, eax ; return value = 0
mov esp, ebp ; restore stack pointer
pop ebp ; restore base pointer (but EBP was overwritten!)
ret 0 ; return (but return address was overwritten too!)
_main ENDP
The result is of course that the program crashes. Let's see exactly where it crashes. We will run it on x32dbg, and to compile it without issues we will use this command:
cl /Od /Zi /GS- /sdl- overflow.c /link /SUBSYSTEM:CONSOLE
; /Od = no optimization
; /Zi = generate debug info
; /GS- = disable stack security cookie (buffer security check)
; /sdl-= disable additional security checks
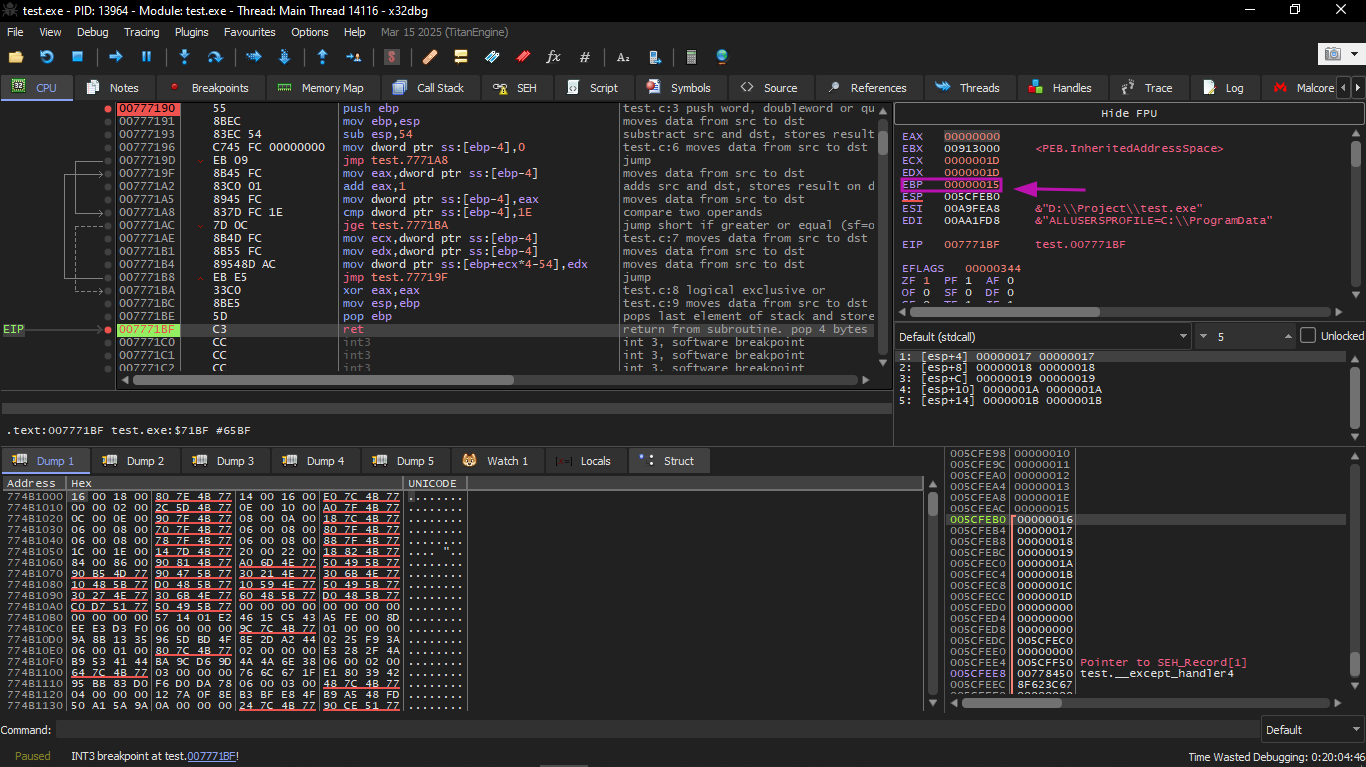
We load the program in x32dbg and follow until it writes all 30 elements:
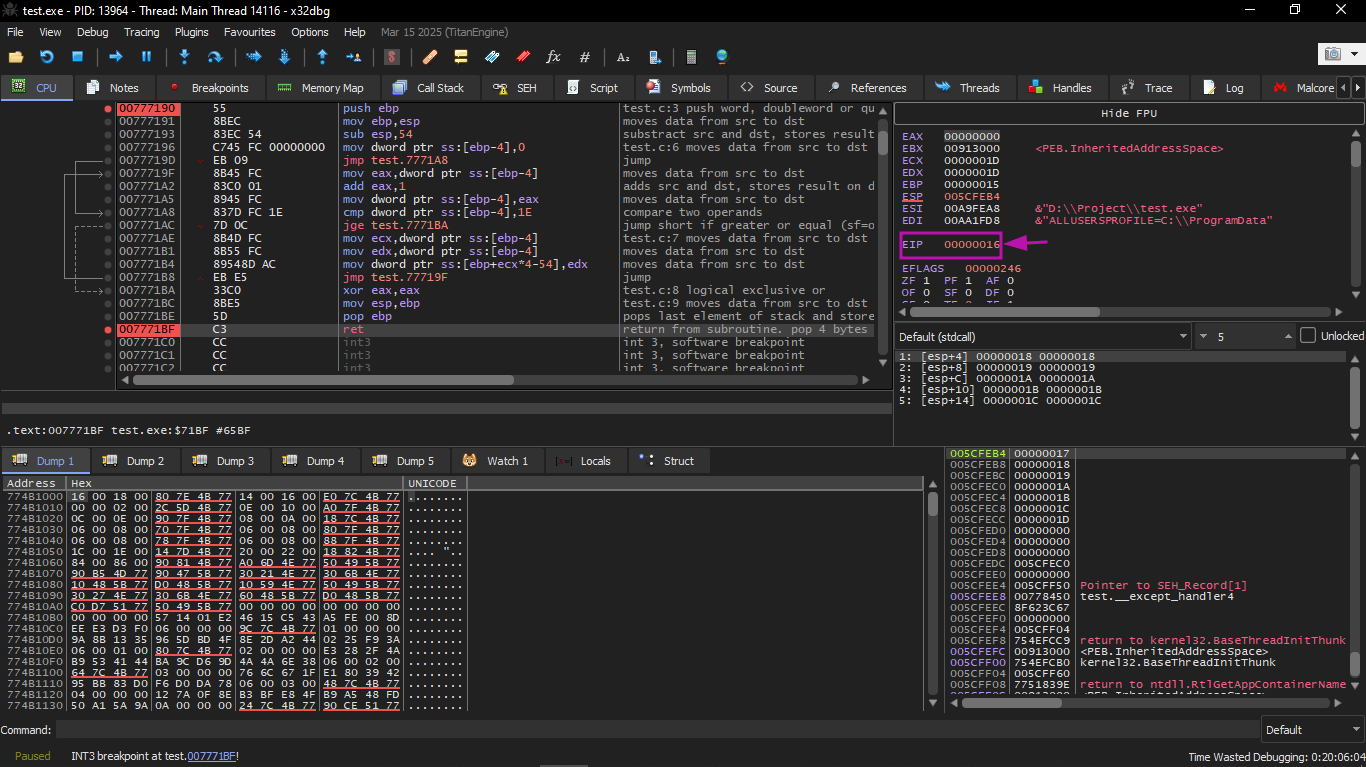
We follow until the end of the function:
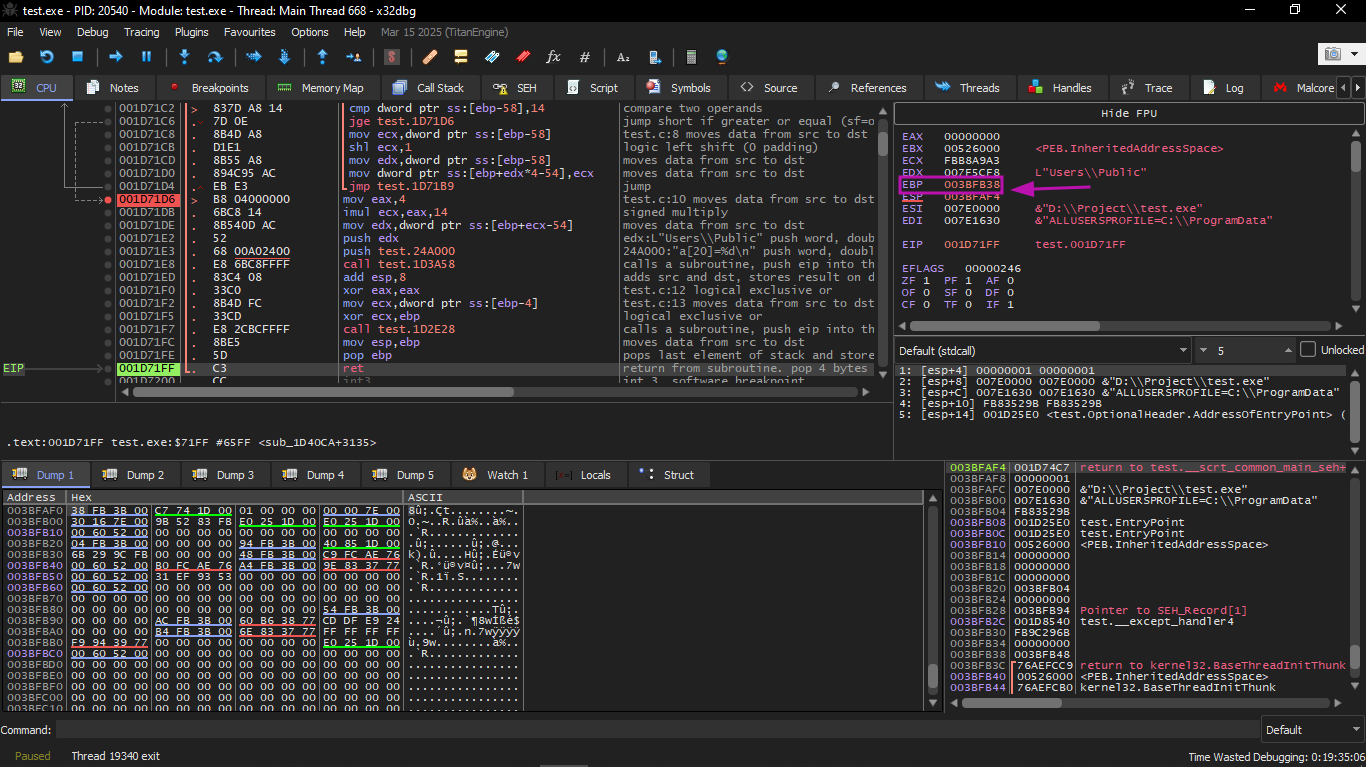
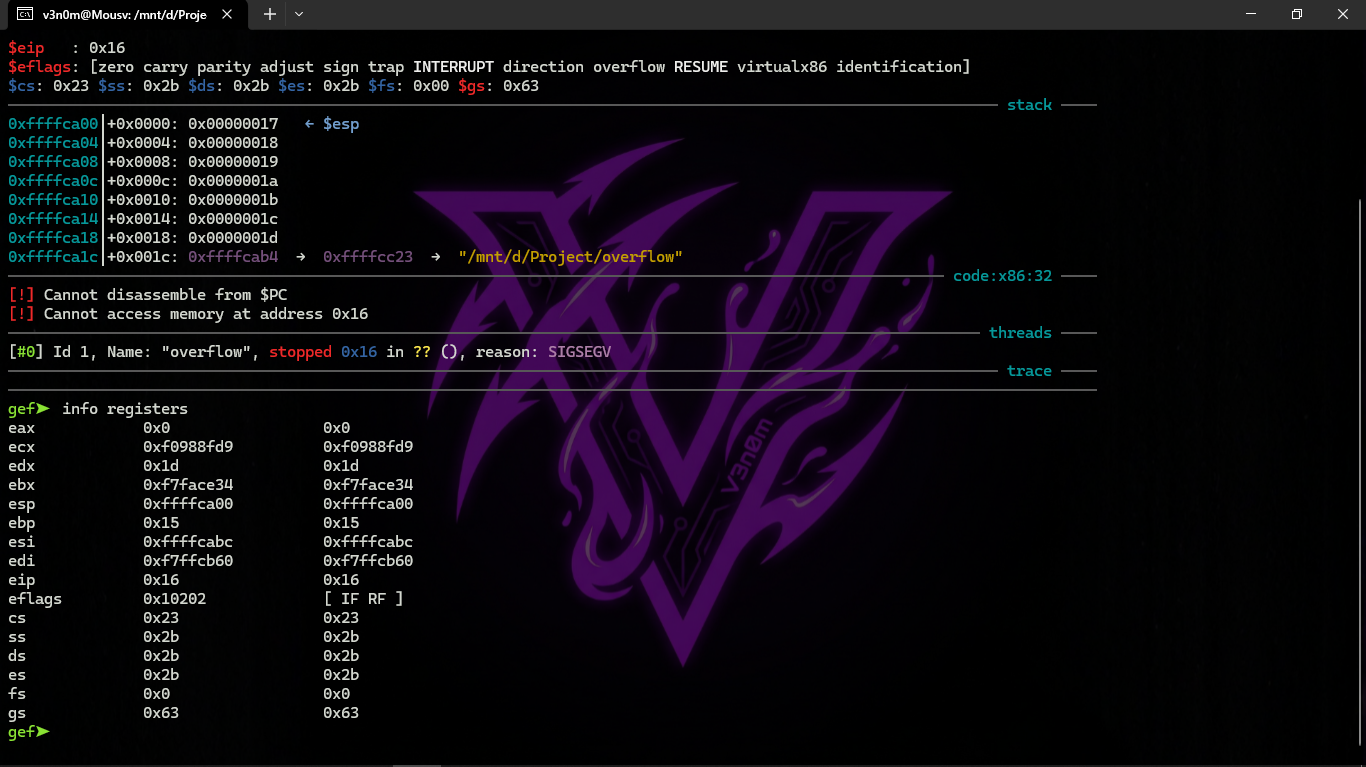
When we focus on the registers we will find that EIP is now 0x16, and that is an illegal address for code (at least in Win32)! We ended up there without intending to. Also EBP became 0x15, and ECX and EDX became 0x1D.
Let's study the stack shape more carefully. After control entered main(), the value of EBP was saved on the stack. Then 84 bytes were allocated for the array and variable i (20+1 elements × 4 bytes). ESP now points to the variable _i, and after any new PUSH, the new thing appears next to it.
This is the shape of the stack while inside main():
The instruction a[19]=something writes the last int inside the array bounds (still safe). The instruction a[20]=something writes to the location that holds the saved value of EBP.
Look at the register state at the time of the crash: in our case, 20 was written into element number 20. At the end of the function, the epilogue restores the old EBP value (decimal 20 = 0x14 hex). Then RET executes, which is essentially like POP EIP. RET takes the return address from the stack (the address in the CRT that called main()), and now in its place is written 21 (0x16 hex). The CPU tries to execute at address 0x16, but there is no executable code there, so an exception occurs.
Welcome to the world of Buffer Overflow!
Replace an int array with a string (char array), intentionally craft a long string, and pass it to a program or function that does not check the string length and copies it into a small buffer, and you can redirect the program to jump to any address you want. It is not easy in practice, but that is the core idea.
GCC
Let's try the same code:
main proc near
a = dword ptr -54h ; array a offset on stack (20 ints = 80 bytes)
i = dword ptr -4 ; variable i offset on stack
push ebp
mov ebp, esp
sub esp, 60h ; allocate 96 bytes on stack
mov [ebp+i], 0 ; i = 0
jmp short loc_80483D1 ; jump to loop condition
loc_80483C3: ; loop body
mov eax, [ebp+i] ; load i as index
mov edx, [ebp+i] ; load i as value
mov [ebp+eax*4+a], edx ; a[i] = i (writes past array end for i >= 20!)
add [ebp+i], 1 ; i++
loc_80483D1: ; loop condition
cmp [ebp+i], 1Dh ; compare i with 29 (0x1D); loop runs 0..29 = 30 iterations
jle short loc_80483C3 ; if i <= 29, continue loop
mov eax, 0 ; return value = 0
leave ; restore stack frame (EBP already corrupted!)
retn ; return (return address already corrupted!)
main endp
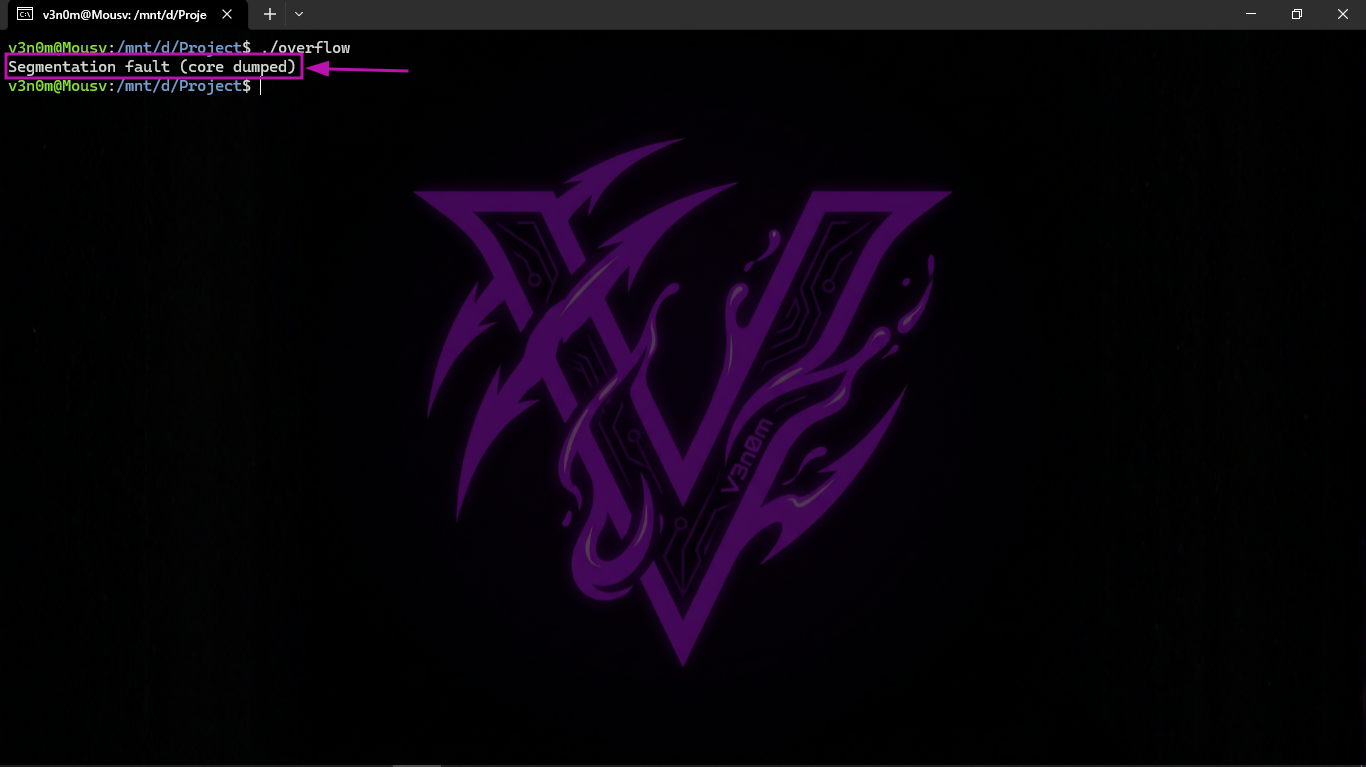
When we run it on Linux it gives us a Segmentation fault (core dumped).
Let's do this practically on Linux and use it as a GDB exercise. First we compile it with this command:
gcc -m32 -O0 -ggdb -fno-stack-protector -z execstack test.c -o overflow
; -m32 = compile as 32-bit
; -O0 = no optimization
; -ggdb = include GDB debug symbols
; -fno-stack-protector = disable stack canary (security cookie)
; -z execstack = allow executable stack (needed for this demo)
And we try to run it:
And indeed it gave a Segmentation fault.
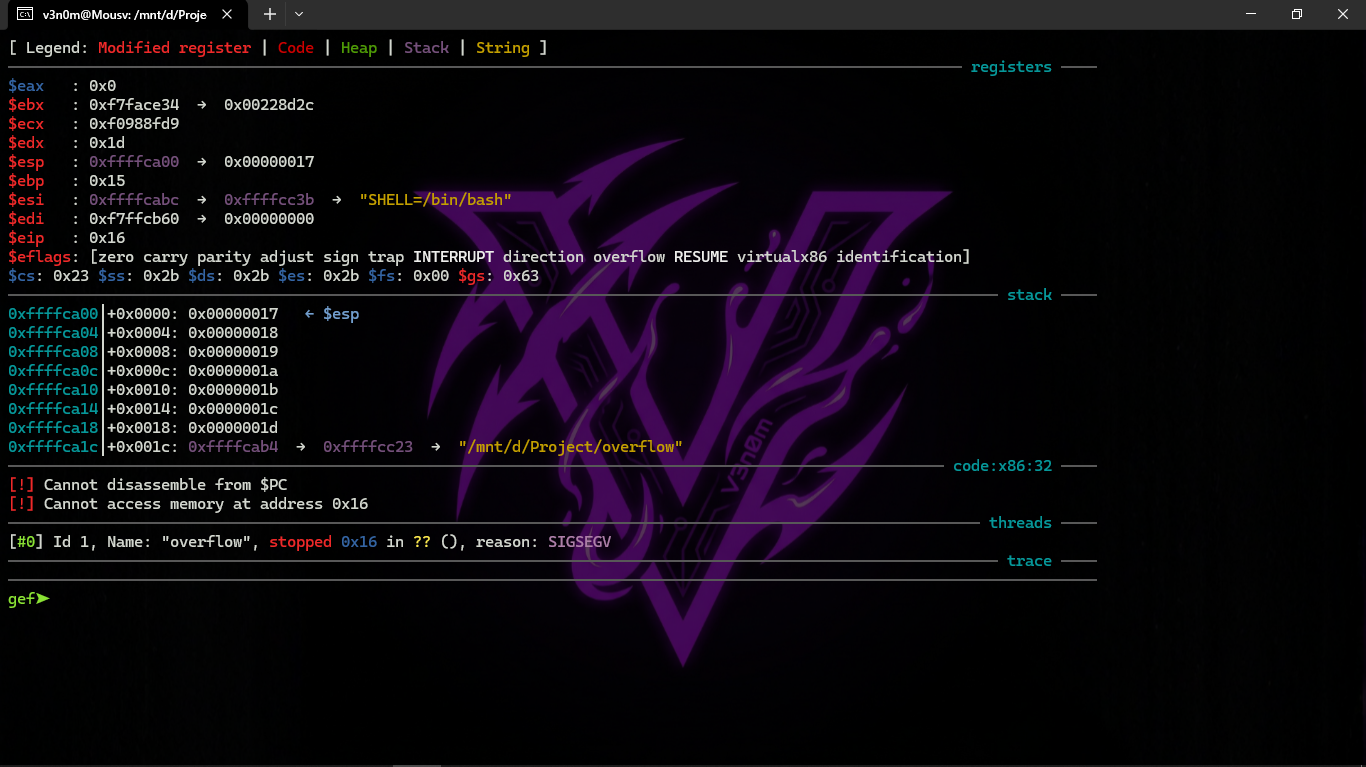
Now let's run it on GDB. First we do gdb overflow then run (or its shortcut r):
We will find it stopped by itself. Now let's look at the registers using info registers:
The register values are slightly different from Win32 because the stack layout is slightly different.
1.26.3 Buffer overflow protection methods
Let's talk about ways to protect against buffer overflow even if the C/C++ programmer is not paying attention.
MSVC has options like these:
* /RTCs → Stack Frame runtime checking
* /GZ → Enable stack checks (same as /RTCs)
One of the methods is that it writes a random value between the local variables on the stack at the beginning of the function (prologue), and then checks it at the end of the function (epilogue) before exiting.
For example, if that value changed → do not execute the last RET instruction, but instead stop the program (or suspend it). The program will stop, but that is much better than someone attacking your machine remotely.
This random value is called a "Canary", and this is connected to the canaries that mine workers used in the old days. They used canaries to detect toxic gases quickly. The canary is very sensitive to gases — if there is danger it becomes very distressed or dies.
If we compile the first example with the /RTC1 and /RTCs options, we will find at the end of the function a call to the function @_RTC_CheckStackVars@8 which checks that the "canary" is still intact.
Now let's see how it is done in GCC:
#ifdef __GNUC__
#include <alloca.h> // GCC: use alloca from alloca.h
#else
#include <malloc.h> // MSVC: use alloca from malloc.h
#endif
#include <stdio.h>
void f() {
char *buf = (char*)alloca(600); // allocate 600 bytes on the stack dynamically
#ifdef __GNUC__
snprintf(buf, 600, "hi! %d, %d, %d\n", 1, 2, 3); // GCC version
#else
_snprintf(buf, 600, "hi! %d, %d, %d\n", 1, 2, 3); // MSVC version
#endif
puts(buf); // print the result
}
Without any extra options, GCC 4.7.3 inserts canary checking code automatically:
Listing 1.235: GCC 4.7.3
.LC0: .string "hi! %d, %d, %d\n" ; format string constant
f:
push ebp ; save base pointer
mov ebp, esp ; set up stack frame
push ebx ; save EBX
sub esp, 676 ; allocate stack space (600 + alignment + canary)
lea ebx, [esp+39] ; EBX = aligned buffer start address
and ebx, -16 ; align buffer to 16-byte boundary
mov DWORD PTR [esp+20], 3 ; push argument 3
mov DWORD PTR [esp+16], 2 ; push argument 2
mov DWORD PTR [esp+12], 1 ; push argument 1
mov DWORD PTR [esp+8], OFFSET FLAT:.LC0 ; push format string address
mov DWORD PTR [esp+4], 600 ; push buffer size
mov DWORD PTR [esp], ebx ; push buffer pointer
mov eax, DWORD PTR gs:20 ; ← load canary value from thread-local storage (TLS)
mov DWORD PTR [ebp-12], eax ; save canary onto stack
xor eax, eax ; clear EAX (security: don't leave canary in register)
call _snprintf ; call snprintf(buf, 600, format, 1, 2, 3)
mov DWORD PTR [esp], ebx ; push buffer pointer
call puts ; call puts(buf)
mov eax, DWORD PTR [ebp-12] ; load canary from stack
xor eax, DWORD PTR gs:20 ; XOR with original canary → result should be 0 if unchanged
jne .L5 ; if not zero (canary was modified), jump to fail handler
mov ebx, DWORD PTR [ebp-4] ; restore EBX
leave ; restore stack frame
ret ; return normally
.L5:
call __stack_chk_fail ; canary was corrupted → terminate program with error
The random value lives in gs:20. It is written onto the stack, and then at the end of the function the value on the stack is compared with the original canary in gs:20. If they are not equal, __stack_chk_fail is called.
In the console (Ubuntu 13.04 x86) it will show something like this:
*** buffer overflow detected ***: ./2_1 terminated
======= Backtrace: =========
/lib/i386-linux-gnu/libc.so.6(__fortify_fail+0x63)[0xb7699bc3]
...
Aborted (core dumped)
In short: in Linux, the gs register always points to TLS (Thread-Local Storage — information specific to the current thread). In win32, the fs register plays the same role and points to TIB.
Optimizing Xcode 4.6.3 (LLVM) (Thumb-2 mode)
Now let's see how LLVM checks the canary:
_main
; local variable offsets:
var_64 = -0x64 ; array element [0]
var_60 = -0x60 ; array element [1]
var_5C = -0x5C ; array element [2]
; ... (more array elements)
canary = -0x14 ; canary value slot on stack
var_10 = -0x10 ; saved R8
PUSH {R4-R7,LR} ; save registers and link register
ADD R7, SP, #0xC ; set frame pointer
STR.W R8, [SP,#0xC+var_10]! ; save R8 on stack
SUB SP, SP, #0x54 ; allocate local stack space
MOVW R0, #aObjc_methtype ; load address of canary source (TLS pointer)
MOVS R2, #0
MOVT.W R0, #0
MOVS R5, #0
ADD R0, PC
LDR.W R8, [R0] ; R8 = pointer to canary source
LDR.W R0, [R8] ; R0 = canary value
STR R0, [SP,#0x64+canary] ; save canary onto stack
; ... (array is filled here with unrolled writes — no loop, each element written individually)
; === canary check at end of function ===
LDR.W R0, [R8] ; reload original canary value
LDR R1, [SP,#0x64+canary] ; load canary copy from stack
CMP R0, R1 ; compare: are they still equal?
ITTTT EQ ; if-then block: execute next 4 instructions only if EQ is true
MOVEQ R0, #0 ; set return value to 0
ADDEQ SP, SP, #0x54 ; deallocate local stack
LDREQ.W R8, [SP+0x64+var_64],#4 ; restore R8
POPEQ {R4-R7,PC} ; restore registers and return normally
BLX ___stack_chk_fail ; canary mismatch → call stack check fail (terminates program)
The first thing we notice: LLVM unrolled the loop and wrote every value into the array one by one, because it calculated that this is faster.
At the end of the function we see the canary comparison (the one on the stack and the one in R8). If they are equal → execute the 4-instruction block (ITTTT EQ) and exit. If they are not equal → go to ___stack_chk_fail which will terminate the program.
1.26.4 One more word about arrays
Now we understand why it is impossible to write something like this in C/C++ code:
void f(int size) {
int a[size]; // ERROR in standard C/C++: size must be known at compile time
...
};
This is because the compiler must know the exact size of the array at compile time, in order to be able to allocate its space on the local stack.
If you need an array with a variable (runtime) size, you must allocate it with malloc(), and then use the allocated block as an array of the desired type:
int *a = (int*)malloc(size * sizeof(int)); // allocate size*4 bytes on the Heap at runtime
// now you can use a[0] through a[size-1] normally
// at the end you must call:
free(a); // release the allocated memory back to the heap
The space is allocated on the Heap (not the stack), and the size can be determined at runtime.
Alternatively, you can use a C99 feature (present in the ISO/IEC 9899:TC3 standard):
void f(int size) {
int a[size]; // Variable Length Array (VLA) — valid in C99 and supported by GCC/Clang
// works internally like alloca() — allocates on the stack
// NOT supported by MSVC
...
}
This works internally like alloca() (allocates on the stack), but it is not available in all compilers (MSVC does not support it).
It is also possible to use Garbage Collection libraries for C, or Smart Pointer libraries in C++. </p </div>