Reverse Engineering for Beginners (CH1.9 Stack)

Stack
The author said at first that the Stack is considered one of the most important data structures in computer science.
It is also known by something called LIFO (Last In, First Out) — the last thing that enters is the first thing that comes out.
Now, technically, it is known that it is considered a part or a piece of memory inside the process memory.
It comes with the ESP register in x86, RSP in x64, and SP in ARM.
Of course, as we said before, they act as pointers within a part of the memory.
The author also said that the most used instructions to access the stack are PUSH and POP (in x86, and also in ARM in Thumb mode).
PUSH subtracts from the ESP/RSP/SP 4 bytes in x86, and in x64 it subtracts 8 bytes, usually putting them in a register, then adds 4 or 8 to the Stack Pointer.
POP is the opposite operation: it takes the data from the memory location that the SP points to, puts it into the operand of the instruction (usually a register), and then adds 4 (or 8) to the Stack Pointer.
Example of Stack Operations
Let me explain the concept with examples because I know it’s a bit complex:
Suppose the stack is empty and the SP points to it like this:
If we do PUSH 10, it will look like this:
Then, if we do PUSH 20, it will be:
When we do POP, it will remove 20 (because it was the last one in), and the SP moves up:
Another Example in Assembly
x86:
First, we took the value 10 and put it into EAX.
Then we did PUSH of 10 from EAX, so now EAX is empty, and the stack contains 10.
Then we repeated the same operation with 20, so now the last value in the stack is 20.
After that, the POP makes the value of EBX equal 20, and the stack now contains 10.
Then, another POP makes the value of ECX equal 10, and the stack becomes empty.
Here is a simple table to illustrate:
ARM Architecture
ARM supports both descending and ascending stacks.
For example, the instructions STMFD/LDMFD and STMED/LDMED are designed to work with a descending stack (grows downwards, starts from a high address and moves to a lower address).
The instructions STMFA/LDMFA and STMEA/LDMEA are designed for an ascending stack (grows upwards, starts from a low address and moves to a higher address).
Why does the stack grow backwards?
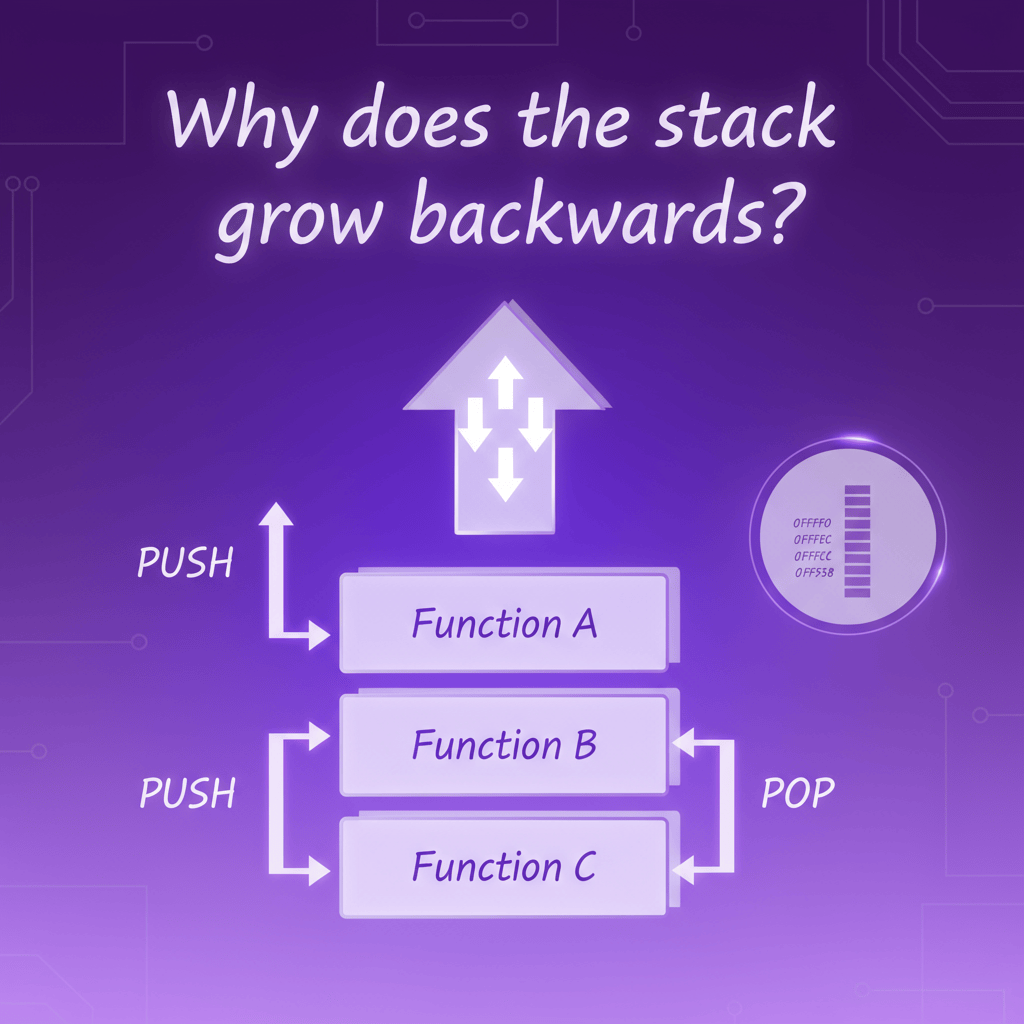
The author explained that if you imagine memory as a number line, you would think that every time you add data to the Stack the address would increase (move right or up). That’s a natural expectation but it’s not what usually happens.
This is because the Stack grows in the opposite direction — not some deep scientific law, but it has a historical reason from the early days of computers.
Long ago computers were large and RAM was very small, so they simply divided memory into two regions: one for the heap and one for the stack.
Of course no one knew in advance how large the heap or the stack would be at runtime, so that split was the simplest possible solution.
A process’s memory is usually divided logically into three areas (segments).
The code segment (the program itself) usually starts from the first virtual address (address zero).
At runtime this segment is write-protected and a single copy of it is shared among all processes running the same program. Immediately after this segment (roughly 8K bytes after it) in the virtual address space the writable data segment begins; it is not shared and its size can grow via system calls.
Starting from the highest address in the virtual address space you find the stack segment, which automatically grows downward according to the hardware stack pointer movements.
The author then said this discussion reminds him of some students who write two lectures in one notebook.
Notes for the first lecture are written normally from the start, and notes for the second lecture are written from the back of the notebook, flipping pages in reverse.
If both write a lot, the notes may meet in the middle and the space runs out.
What is the stack used for?
The author then said that the Stack is used to store the return address that a function should go back to after it finishes.
When you call another function with the CALL instruction, the address immediately after the CALL is stored on the stack, and then an unconditional jump to the address in the CALL occurs.
A CALL instruction is equivalent to doing a PUSH of the address after the CALL and then JMP to the function’s address.
A RET pulls a value from the stack and jumps to it — like doing POP tmp and then JMP tmp.
Here is an example of a function that can cause a Stack Overflow:
Then the compiler will notice there is a problem (infinite recursion / potential stack overflow). Nevertheless, it still emits assembly code, for example:
If we enable compiler optimization /Ox, the code becomes faster and will not cause stack overflow:
ARM
The author said that ARM also uses the stack to store return addresses, but it does it in a slightly different way from x86.
And we have already said before that in ARM, the address that the function should return to after finishing is not always placed on the stack — it’s placed in a register called LR (link register).
Let’s simplify things a bit:
- If the function does not call any other functions → it can work without touching the stack at all (leaf function), LR stays fixed and there’s no need to save it.
- If the function will call another function → when it executes BL inside it, LR will change (it will store the return address of the new function). So, if you want to return later to your original place, you must save LR before calling.
And usually, it’s saved in the prologue.
And most likely, we will see these instructions:
And along with it, at the end:
Passing function arguments
When we call a function in C like this:
The arguments (that is, 10, 20, and 30) must be stored somewhere so that the function can use them internally.
In x86 (32-bit) and under the cdecl convention, the most common way is to put them in the stack.
And the compiler handles it like this:
Why 12?
Because each argument is 4 bytes in size → 3 * 4 = 12.
When f() starts to execute, the stack looks like this:
That means inside the function you can access the parameters starting from ESP+4.
And the function being called has no idea how many arguments the caller sent; it just assumes what’s declared in the code:
That means it will read only 3, even if the caller sent more.
And this is the same situation with printf() for example — it knows the number through the format string that begins with %.
So, if we write for example:
It will print 1234 and then two random numbers that were beside it in the stack.
That’s why it’s not very important how you declare main(): whether main(), or main(int argc, char *argv[]), or main(int argc, char *argv[], char *envp[]).
And generally, in practice, the CRT code calls main() roughly like this:
If you declare main() without parameters, the arguments will still exist on the stack but you simply don’t use them. If you declare main(int argc, char *argv[]), you will be able to use the first two, and the third will remain “invisible” to you. You can even declare main(int argc) and it will still work.
Alternative ways of passing arguments
The author also mentioned that this whole stack mechanism is not mandatory for programmers — a programmer can use any other method without using the stack at all.
Let’s mention one of the ways that some beginners in assembly use:
They pass the parameters through global variables.
Like this, for example:
But unfortunately, this method has a problem:
The function do_something() won’t be able to call itself (i.e., perform recursion), because it overwrites the same variables that hold the parameters.
The same applies if you also put local variables in global variables — the function will not be able to call itself.
Also, this method is not safe in threads (i.e., when multiple threads are running at the same time).
Using the stack, however, makes this easier, because it can hold an unlimited number of parameters or values (depending on how much space the stack occupies).
In the old days of MS-DOS, all parameters were passed through registers, not the stack.
Like in this example:
This method is very close to the one used by Linux and Windows in system calls.
And if this function wanted to return a Boolean value (i.e., True/False), they used the CF (Carry Flag).
Like this:
If an error occurred, CF is set (i.e., = 1). And if no error occurred, the function returns the file handle in AX.
This method is still used by some people in assembly even today. And in the Windows kernel code, there are functions that work with the same principle.
Local variable storage
A function can allocate space in the stack for local variables simply by decreasing the value of the Stack Pointer (ESP or RSP).
And this operation is extremely fast regardless of the number of variables.
Also, it’s not mandatory to store local variables in the stack; you can store them anywhere else.
But by habit and programming convention, the stack is what’s usually used.
x86: alloca() function
First of all, the alloca() function allocates n bytes on the stack instead of the heap and returns a pointer to the allocated block.
It works like malloc, but the storage location is different.
You don’t need to call free() for the memory allocated with alloca. Why? Because when the function that called alloca finishes, the epilogue restores ESP to its original position — meaning that the space allocated is “discarded” and becomes unavailable afterward.
And of course, it’s faster than malloc because it operates directly on the stack.
MSVC
Let’s try compiling the code using MSVC 2010:
The only argument for the alloca() function is passed via the EAX register, instead of placing it on the stack using push.
GCC + Intel syntax
The compiler performs the same operation without calling any external functions:
GCC + AT&T syntax
The same code, but written in AT&T syntax.
(Listing 1.42: GCC 4.7.3)
The code is identical to the Intel version, except for the syntax — in AT&T, addresses use the form offset(%reg) instead of [reg+offset].
For example, movl $3, 20(%esp) in AT&T corresponds to mov DWORD PTR [esp+20], 3 in Intel syntax.
By the way, the SEH (Structured Exception Handling) records are also stored on the stack (if they exist).
The possible reason for storing both local variables and SEH records on the stack is that they can be automatically cleaned up when the function ends — usually with a single instruction that restores the stack pointer (commonly an ADD).
Function arguments are also automatically released at the end of the function. In contrast, anything allocated on the heap must be explicitly freed using free().
1.9.3 A typical stack layout
Here’s what the stack typically looks like in a 32-bit environment at the very start of a function, before executing the first instruction:
--------------------------------------------------------------------------- | ESP-0xC | local variable#2, marked in IDA as var_8 | | ESP-8 | local variable#1, marked in IDA as var_4 | | ESP-4 | saved value of EBP | | ESP | Return Address | | ESP+4 | argument#1, marked in IDA as arg_0 | | ESP+8 | argument#2, marked in IDA as arg_4 | | ESP+0xC | argument#3, marked in IDA as arg_8 | ---------------------------------------------------------------------------
Noise in Stack
When we say there is noise or garbage in the stack, it doesn’t mean the computer created random numbers in the mathematical sense. It means that a certain area in memory contains leftover values from something that was executed earlier — values that are not clearly related to the current program. In other words, they are uninitialized and therefore appear “random” to you.
A simple example:
Then we compile it:
At this point, the compiler will complain a little:
The reason is that you are reading a local variable without initializing it — this is undefined behavior in C. The warning simply means: “Be careful, you might get unexpected values.”
Stack state visualization
Before any function executes:
ESP → empty
When f1() runs:
ESP-4 → c = 3 ESP-8 → b = 2 ESP-12 → a = 1
When f2() runs:
ESP-4 → c (uninitialized, actually still has value 3) ESP-8 → b (uninitialized, still has value 2) ESP-12 → a (uninitialized, still has value 1)
See? f2’s variables still point to the same stack space as f1’s — that’s why the old values appear again.
To avoid this, simply initialize the variables directly:
MSVC 2013
The example was originally compiled using MSVC 2010, but a reader of the book tried compiling the same example with MSVC 2013, ran it, and got the output reversed:
After compiling with MSVC 2013, the result looked like this:
Unlike MSVC 2010, the MSVC 2013 compiler allocated the variables a, b, c in reverse order within f2(). This is perfectly fine, since the C/C++ standard does not specify the order of local variable storage on the stack — or even whether they must be stored there at all. The difference comes from how MSVC 2010 handled variable layout internally, while MSVC 2013 changed its compiler behavior slightly.