







1.22.1 Small number of cases
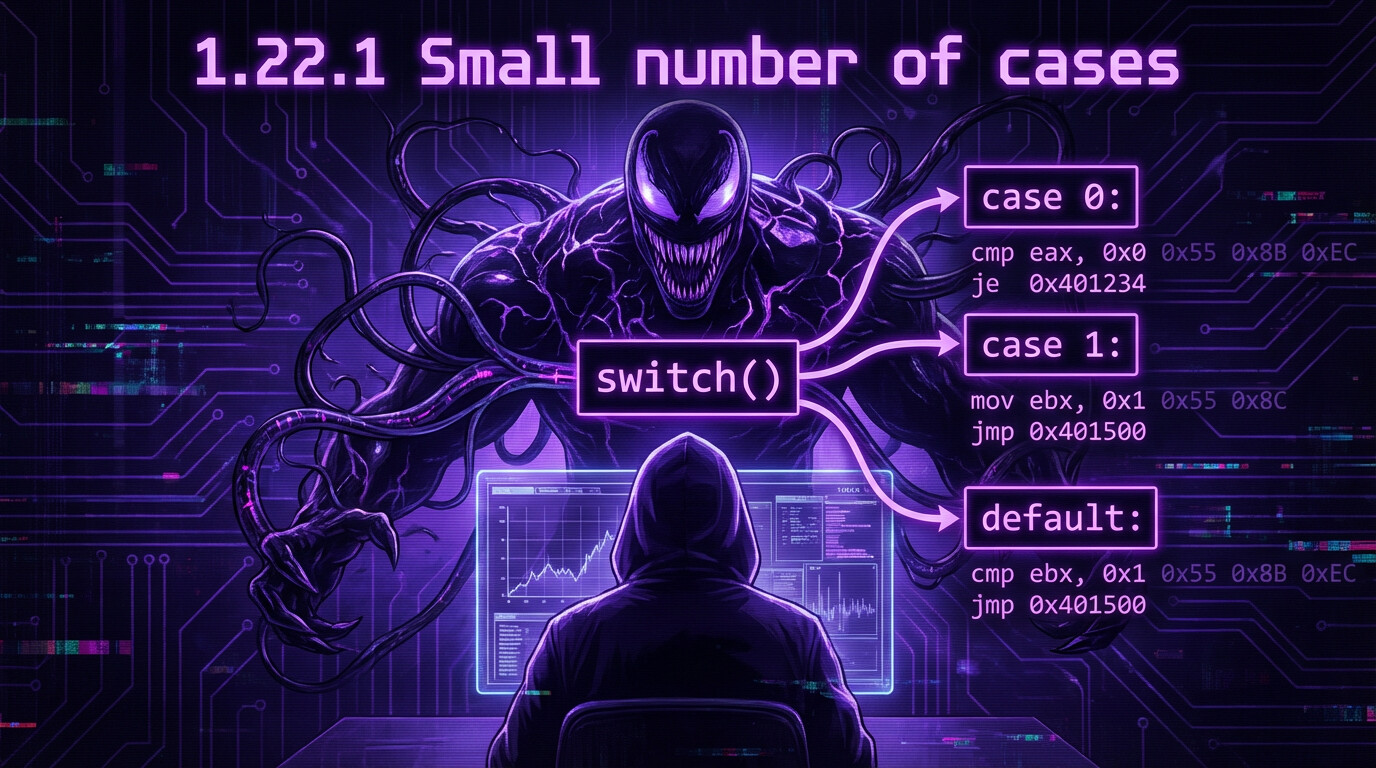
#include <stdio.h> // include standard I/O header
void f (int a) // define function f taking int a{ switch (a) // switch on value of a { case 0: printf ("zero\n"); break; // if a==0, print "zero" and break case 1: printf ("one\n"); break; // if a==1, print "one" and break case 2: printf ("two\n"); break; // if a==2, print "two" and break default: printf ("something unknown\n"); break; // otherwise print "something unknown" and break };};
int main() // program entry point{ f (2); // test with value 2};x86: Non-optimizing MSVC
tv64 = -4 ; temporary variable offset_a$ = 8 ; parameter a offset_f PROC push ebp ; save EBP mov ebp, esp ; set up stack frame push ecx ; allocate space for temporary
mov eax, DWORD PTR _a$[ebp] ; load a into EAX mov DWORD PTR tv64[ebp], eax ; store copy in temporary tv64
cmp DWORD PTR tv64[ebp], 0 ; compare temporary with 0 je SHORT $LN4@f ; if equal, jump to zero case
cmp DWORD PTR tv64[ebp], 1 ; compare with 1 je SHORT $LN3@f ; if equal, jump to one case
cmp DWORD PTR tv64[ebp], 2 ; compare with 2 je SHORT $LN2@f ; if equal, jump to two case
jmp SHORT $LN1@f ; otherwise jump to default
$LN4@f: ; zero case push OFFSET $SG739 ; push address of "zero\n" call _printf ; call printf add esp, 4 ; clean up stack jmp SHORT $LN7@f ; jump to exit
$LN3@f: ; one case push OFFSET $SG741 ; push address of "one\n" call _printf ; call printf add esp, 4 ; clean up stack jmp SHORT $LN7@f ; jump to exit
$LN2@f: ; two case push OFFSET $SG743 ; push address of "two\n" call _printf ; call printf add esp, 4 ; clean up stack jmp SHORT $LN7@f ; jump to exit
$LN1@f: ; default case push OFFSET $SG745 ; push address of "something unknown\n" call _printf ; call printf add esp, 4 ; clean up stack
$LN7@f: ; function exit mov esp, ebp ; restore ESP pop ebp ; restore EBP ret 0 ; return_f ENDP
This function with a small number of cases in switch() will look like this:
void f (int a){ if (a==0) printf ("zero\n"); else if (a==1) printf ("one\n"); else if (a==2) printf ("two\n"); else printf ("something unknown\n");};
The author began explaining that when dealing with a switch() with a small number of cases, it is impossible to determine whether the source code actually contained a switch() or just several if() statements chained together.
This means that switch() is merely syntactic sugar for a large number of nested if() statements.
There is nothing particularly new in the generated code, except that the compiler copied the value of variable a to a temporary local variable named tv64. If we compile this with GCC 4.4.1, even with maximum optimization (-O3), the result will be very similar.
Optimizing MSVC
Now let us enable optimization in MSVC using /Ox:
cl 1.c /Fa1.asm /Ox_a$ = 8 ; parameter a offset_f PROC mov eax, DWORD PTR _a$[esp-4] ; load a into EAX sub eax, 0 ; subtract 0 (sets flags for comparison with 0) je SHORT $LN4@f ; if result zero (a==0), jump to zero case
sub eax, 1 ; subtract 1 je SHORT $LN3@f ; if result zero (a==1), jump to one case
sub eax, 1 ; subtract 1 again je SHORT $LN2@f ; if result zero (a==2), jump to two case
mov DWORD PTR _a$[esp-4], OFFSET $SG791 ; load address of "something unknown\n" jmp _printf ; jump to printf
$LN2@f: ; two case mov DWORD PTR _a$[esp-4], OFFSET $SG789 ; load address of "two\n" jmp _printf ; jump to printf
$LN3@f: ; one case mov DWORD PTR _a$[esp-4], OFFSET $SG787 ; load address of "one\n" jmp _printf ; jump to printf
$LN4@f: ; zero case mov DWORD PTR _a$[esp-4], OFFSET $SG785 ; load address of "zero\n" jmp _printf ; jump to printf_f ENDPLet us simply explain what happened here:
First:
The value of a is placed in the EAX register, then:
sub eax, 0This looks strange, but the goal is to test whether the value is zero.
- If the result is zero → ZF flag is set
- Then the
JE(Jump if Equal or JZ) instruction works - And we jump directly to label
$LN4@f - And "zero" is printed
If the jump did not occur:
- Subtract 1
- Then subtract 1 again
- As soon as the result becomes zero → the appropriate jump occurs
If no jump occurred, print "something unknown".
Second:
We see that the string address is placed in the variable a itself, then printf() is called with JMP instead of CALL.
Why?
- The caller of function
f()did: CALL f- This pushed the return address (RA) onto the stack
- While
f()is executing, the stack layout is: - ESP → return address
- ESP+4 → variable a
- When calling
printf(): - We need exactly the same stack layout
- But the difference is that the first argument should be the string address
This is what the code did:
- Replaced the value of
awith the string address - Jumped directly with
JMPtoprintf()
printf() prints the string and then executes RET, popping the return address from the stack and returning directly to the caller of f() without returning to f() itself. Thus f() is completely bypassed at the end. This technique is somewhat similar to the idea of longjmp(), and of course it is all done for speed.
We can summarize this a bit: if the last thing in a function is a call to another function with no code after it, the compiler can:
- Modify the arguments
- Jump with
JMP - And let
REThappen from the other function
x32dbg (EX2)
Note: I could not get this example to work perfectly because the compiler is newer than the one in the book, which made a slight difference. I will try to explain the example as much as possible.
We run the same example in x32dbg after compiling and start running it in the debugger.
EAX value is 2 initially, which is the input value of the function.
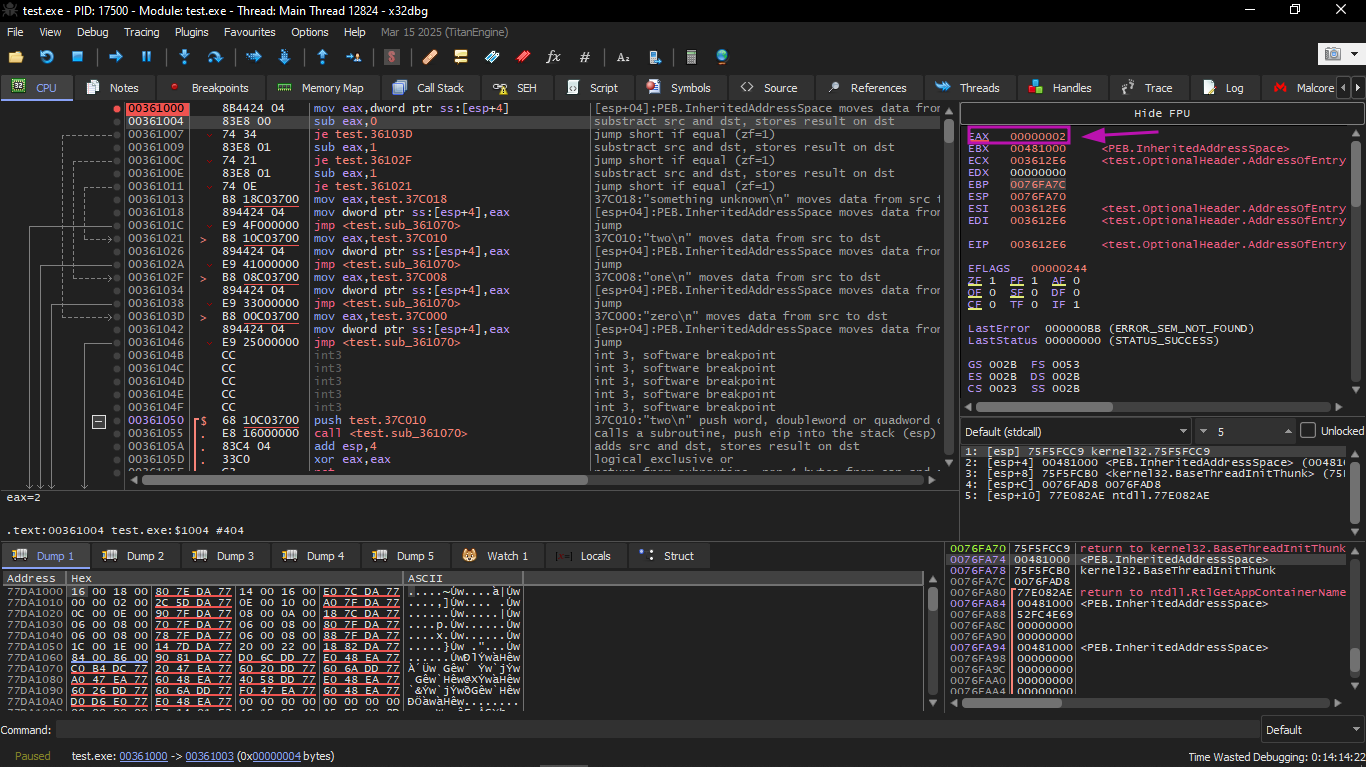
0 is subtracted from 2 in EAX. Of course, EAX still has 2. But the ZF flag is now 0, meaning the result is not zero:
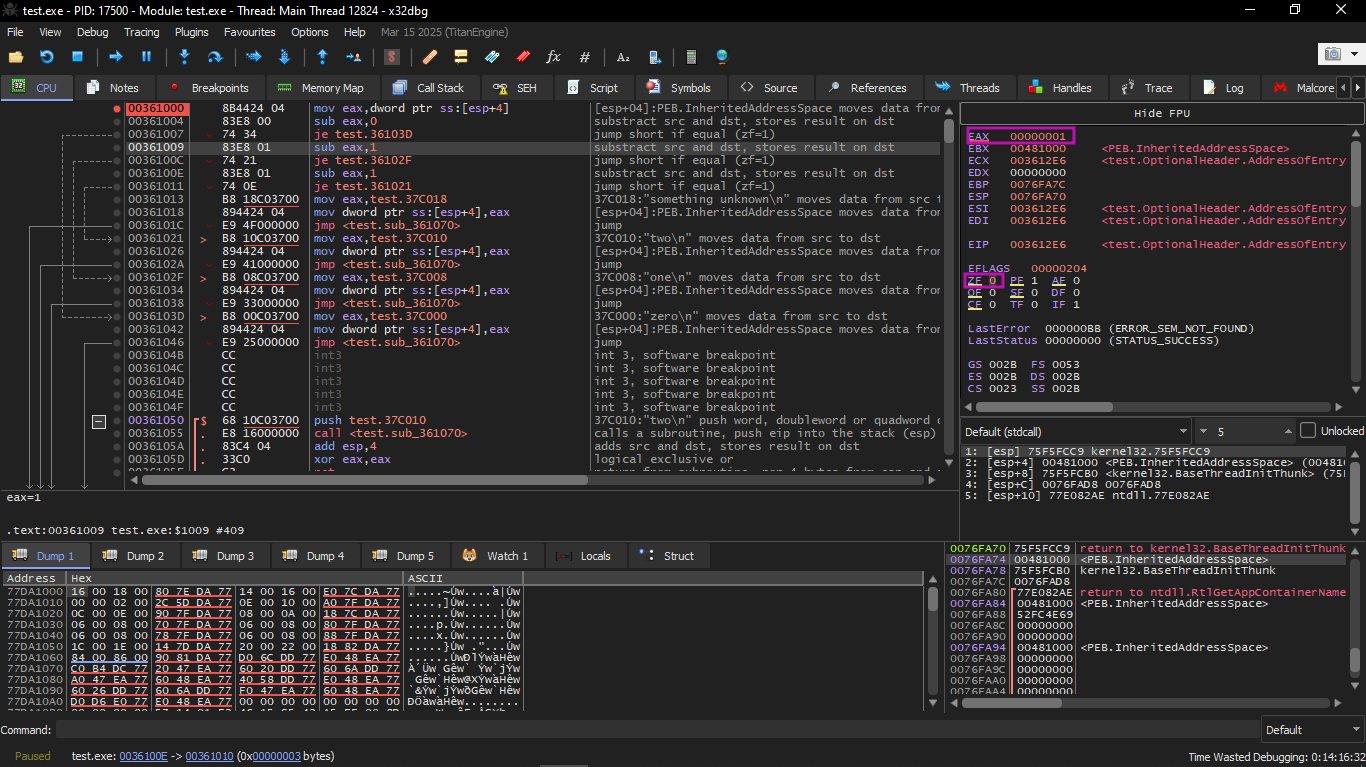
Then another SUB is performed. EAX finally becomes 0 and the ZF flag is set because the result became zero:
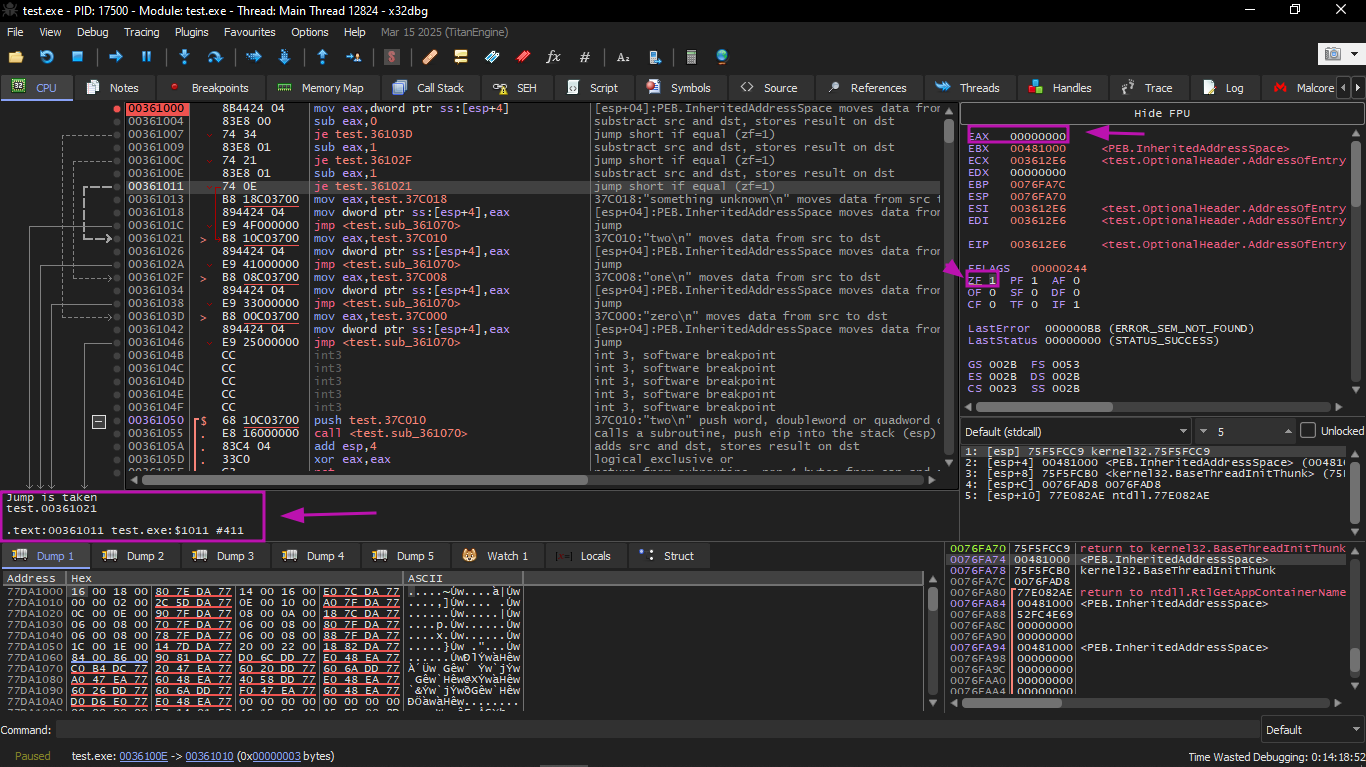
Now the current argument to the function is 2, and 2 is currently on the stack.
The pointer to the string is written, and then the jump occurs. This is the first instruction in printf() in MSVCR100.DLL.
After that, printf() takes the string as the only argument and prints it. This is the last instruction in printf().
The string "two" is now printed on the console window.
And the jump was direct from inside printf() to main() because the RA on the stack does not point to a location in f(), but points to main().
ARM: Optimizing Keil 6/2013 (ARM mode)
.text:0000014C f1: CMP R0, #0 ; compare input with 0 ADREQ R0, aZero ; if equal, load address of "zero\n" into R0 BEQ loc_170 ; if equal, jump to printf call
CMP R0, #1 ; compare with 1 ADREQ R0, aOne ; if equal, load address of "one\n" BEQ loc_170 ; if equal, jump to printf
CMP R0, #2 ; compare with 2 ADRNE R0, aSomethingUnkno ; if not equal, load address of "something unknown\n" ADREQ R0, aTwo ; if equal, load address of "two\n"
loc_170: B __2printf ; unconditional jump to printf
Again, looking at this code we cannot determine whether it was a switch() or just several if statements.
In general, we see conditional instructions here (like ADREQ which means "Equal") which execute only if R0 = 0, and then load the address of the string "zero\n" into R0.
The following BEQ instruction transfers control to loc_170 if R0 = 0.
The question is: will BEQ work correctly since ADREQ just changed the value of R0 before it?
Yes, it will work because BEQ checks the flags set by the CMP instruction, and ADREQ does not change any flags at all.
The rest of the instructions are familiar to us. There is only one call to printf() at the end, and we have explained this trick before.
In the end, there are 3 paths leading to printf().
The last CMP R0, #2 instruction exists to check if a = 2. If not, the ADRNE instruction loads the pointer to the string "something unknown\n" into R0, since we are sure at this stage that the variable a is not equal to those numbers.
If R0 = 2, the pointer to the string "two\n" will be loaded into R0 via ADREQ.
ARM: Optimizing Keil 6/2013 (Thumb mode)
.text:000000D4 f1: PUSH {R4, LR} ; save R4 and LR
CMP R0, #0 ; compare input with 0 BEQ zero_case ; if equal, jump to zero case
CMP R0, #1 ; compare with 1 BEQ one_case ; if equal, jump to one case
CMP R0, #2 ; compare with 2 BEQ two_case ; if equal, jump to two case
ADR R0, aSomethingUnkno ; load address of "something unknown\n" B default_case ; jump to printf call
zero_case: ADR R0, aZero ; load address of "zero\n" B default_case ; jump to printf call
one_case: ADR R0, aOne ; load address of "one\n" B default_case ; jump to printf call
two_case: ADR R0, aTwo ; load address of "two\n"
default_case: BL __2printf ; call printf POP {R4, PC} ; restore R4 and returnAs mentioned before, it is not possible to add conditional predicates to most instructions in Thumb mode, so the Thumb code here is similar to CISC-style x86 code and is very easy to understand.
ARM64: Non-optimizing GCC (Linaro) 4.9
.LC12: .string "zero".LC13: .string "one".LC14: .string "two".LC15: .string "something unknown"
f12: stp x29, x30, [sp, -32]! ; save frame pointer and link register add x29, sp, 0 ; set frame pointer
str w0, [x29, 28] ; store input argument on stack ldr w0, [x29, 28] ; load it back into W0
cmp w0, #1 ; compare with 1 beq .L34 ; if equal, jump to one case
cmp w0, #2 ; compare with 2 beq .L35 ; if equal, jump to two case
cmp w0, wzr ; compare with zero (WZR is always zero) bne .L38 ; if not zero, jump to default
adrp x0, .LC12 ; load page address of "zero" add x0, x0, :lo12:.LC12 ; add low 12 bits offset bl puts ; call puts b .L32 ; jump to exit
.L34: ; one case adrp x0, .LC13 ; load page address of "one" add x0, x0, :lo12:.LC13 bl puts b .L32
.L35: ; two case adrp x0, .LC14 ; load page address of "two" add x0, x0, :lo12:.LC14 bl puts b .L32
.L38: ; default case adrp x0, .LC15 ; load page address of "something unknown" add x0, x0, :lo12:.LC15 bl puts nop ; no operation
.L32: ; function exit ldp x29, x30, [sp], 32 ; restore FP/LR and deallocate ret ; returnThe input value type is int, so the W0 register is used instead of the full X0 register.
String pointers are passed to puts() using the ADRP/ADD pair of instructions.
ARM64: Optimizing GCC (Linaro) 4.9
f12: cmp w0, #1 ; compare input with 1 beq .L31 ; if equal, jump to one case
cmp w0, #2 ; compare with 2 beq .L32 ; if equal, jump to two case
cbz w0, .L35 ; compare and branch if zero (jump to zero case)
; default case adrp x0, .LC15 ; load page address of "something unknown" add x0, x0, :lo12:.LC15 b puts ; unconditional jump to puts
.L35: ; zero case adrp x0, .LC12 ; load page address of "zero" add x0, x0, :lo12:.LC12 b puts ; jump to puts
.L32: ; two case adrp x0, .LC14 ; load page address of "two" add x0, x0, :lo12:.LC14 b puts ; jump to puts
.L31: ; one case adrp x0, .LC13 ; load page address of "one" add x0, x0, :lo12:.LC13 b puts ; jump to puts
More optimized code. The CBZ (Compare and Branch on Zero) instruction jumps if W0 is zero.
There is also a direct jump to puts() instead of calling it, as explained before.
MIPS
f: lui $gp, (__gnu_local_gp >> 16) ; load upper 16 bits of global pointer
; is it 1? li $v0, 1 ; load immediate 1 into $v0 beq $a0, $v0, loc_60 ; if input == 1, jump to one case la $gp, (__gnu_local_gp & 0xFFFF) ; load lower bits (delay slot)
; is it 2? li $v0, 2 ; load immediate 2 beq $a0, $v0, loc_4C ; if input == 2, jump to two case or $at, $zero ; NOP (delay slot)
; jump if not equal to 0 bnez $a0, loc_38 ; if input != 0, jump to default or $at, $zero ; NOP (delay slot)
; zero case lui $a0, ($LC0 >> 16) ; load upper bits of "zero" address lw $t9, (puts & 0xFFFF)($gp) ; load puts address from global pointer or $at, $zero ; NOP (load delay slot) jr $t9 ; jump to puts (delay slot) la $a0, ($LC0 & 0xFFFF) ; load lower bits of "zero" (delay slot)
loc_38: ; default case lui $a0, ($LC3 >> 16) ; load upper bits of "something unknown" lw $t9, (puts & 0xFFFF)($gp) ; load puts address or $at, $zero ; NOP jr $t9 ; jump to puts la $a0, ($LC3 & 0xFFFF) ; load lower bits (delay slot)
loc_4C: ; two case lui $a0, ($LC2 >> 16) ; load upper bits of "two" lw $t9, (puts & 0xFFFF)($gp) ; load puts address or $at, $zero ; NOP jr $t9 ; jump to puts la $a0, ($LC2 & 0xFFFF) ; load lower bits (delay slot)
loc_60: ; one case lui $a0, ($LC1 >> 16) ; load upper bits of "one" lw $t9, (puts & 0xFFFF)($gp) ; load puts address or $at, $zero ; NOP jr $t9 ; jump to puts la $a0, ($LC1 & 0xFFFF) ; load lower bits (delay slot)
This function always ends with a call to puts(), so we see a direct jump to puts() (JR means Jump Register) instead of using "jump and link".
We also see many NOP instructions after LW instructions. This is called a load delay slot: another type of delay slot in MIPS.
The instruction after LW can execute simultaneously while LW is still loading the value from memory. But the instruction after that cannot use the result just loaded by LW.
Modern MIPS processors have a feature to stall if the next instruction uses the result of LW, so this issue is considered obsolete. But GCC still adds NOP instructions to support older MIPS processors.
1.22.2 A lot of cases

If the switch() statement has many cases, it is not convenient for the compiler to generate large code with many JE/JNE instructions.
#include <stdio.h>
void f (int a){ switch (a) { case 0: printf ("zero\n"); break; case 1: printf ("one\n"); break; case 2: printf ("two\n"); break; case 3: printf ("three\n"); break; case 4: printf ("four\n"); break; default: printf ("something unknown\n"); break; };};
int main(){ f (2); // test};x86: Non-optimizing MSVC
tv64 = -4 ; temporary variable_a$ = 8 ; parameter a offset_f PROC push ebp mov ebp, esp push ecx
mov eax, DWORD PTR _a$[ebp] ; load a mov DWORD PTR tv64[ebp], eax ; store in temporary
cmp DWORD PTR tv64[ebp], 4 ; compare with maximal case value (4) ja SHORT $LN1@f ; if greater, jump to default
mov ecx, DWORD PTR tv64[ebp] ; load temporary into ECX jmp DWORD PTR $LN11@f[ecx*4] ; indirect jump using jump table
$LN6@f: ; case 0 push OFFSET $SG739 ; "zero" call _printf add esp, 4 jmp SHORT $LN9@f
$LN5@f: ; case 1 push OFFSET $SG741 ; "one" call _printf add esp, 4 jmp SHORT $LN9@f
$LN4@f: ; case 2 push OFFSET $SG743 ; "two" call _printf add esp, 4 jmp SHORT $LN9@f
$LN3@f: ; case 3 push OFFSET $SG745 ; "three" call _printf add esp, 4 jmp SHORT $LN9@f
$LN2@f: ; case 4 push OFFSET $SG747 ; "four" call _printf add esp, 4 jmp SHORT $LN9@f
$LN1@f: ; default case push OFFSET $SG749 ; "something unknown" call _printf add esp, 4
$LN9@f: ; function exit mov esp, ebp pop ebp ret 0
npad 2 ; align next label
$LN11@f: DD $LN6@f ; table entry for case 0 DD $LN5@f ; case 1 DD $LN4@f ; case 2 DD $LN3@f ; case 3 DD $LN2@f ; case 4_f ENDP
What we see here is a set of printf() calls with different arguments. Each not only has a memory address in the process, but also internal symbolic labels generated by the compiler. All these labels are also listed in an internal table named $LN11@f.
At the beginning of the function, if a is greater than 4, control flow is passed to label $LN1@f, where printf() is called with the argument "something unknown".
But if the value of a is less than or equal to 4, it is multiplied by 4 and added to the address of table $LN11@f. This forms an address inside the table that points exactly to the element we need.
For example, let us say a equals 2.
2 * 4 = 8 (each table element is an address in a 32-bit process, so each element is 4 bytes in size). The address of table $LN11@f + 8 is the table element that stores the label named $LN4@f. The JMP instruction fetches the address $LN4@f from the table and jumps there.
This table is sometimes called a jumptable or branch table.
Then the appropriate printf() is called with the argument "two".
Literally, the instruction:
jmp DWORD PTR $LN11@f[ecx*4]
means: jump to the DWORD stored at address $LN11@f + ecx * 4.
npad is a macro in assembly language that aligns the next label to a 4-byte (or 16-byte) boundary. This is very suitable for the processor because it can fetch 32-bit values from memory via the memory bus, cache memory, etc., more efficiently when they are aligned.
x32dbg
We run the same example in x32dbg after compiling and start running it in the debugger.
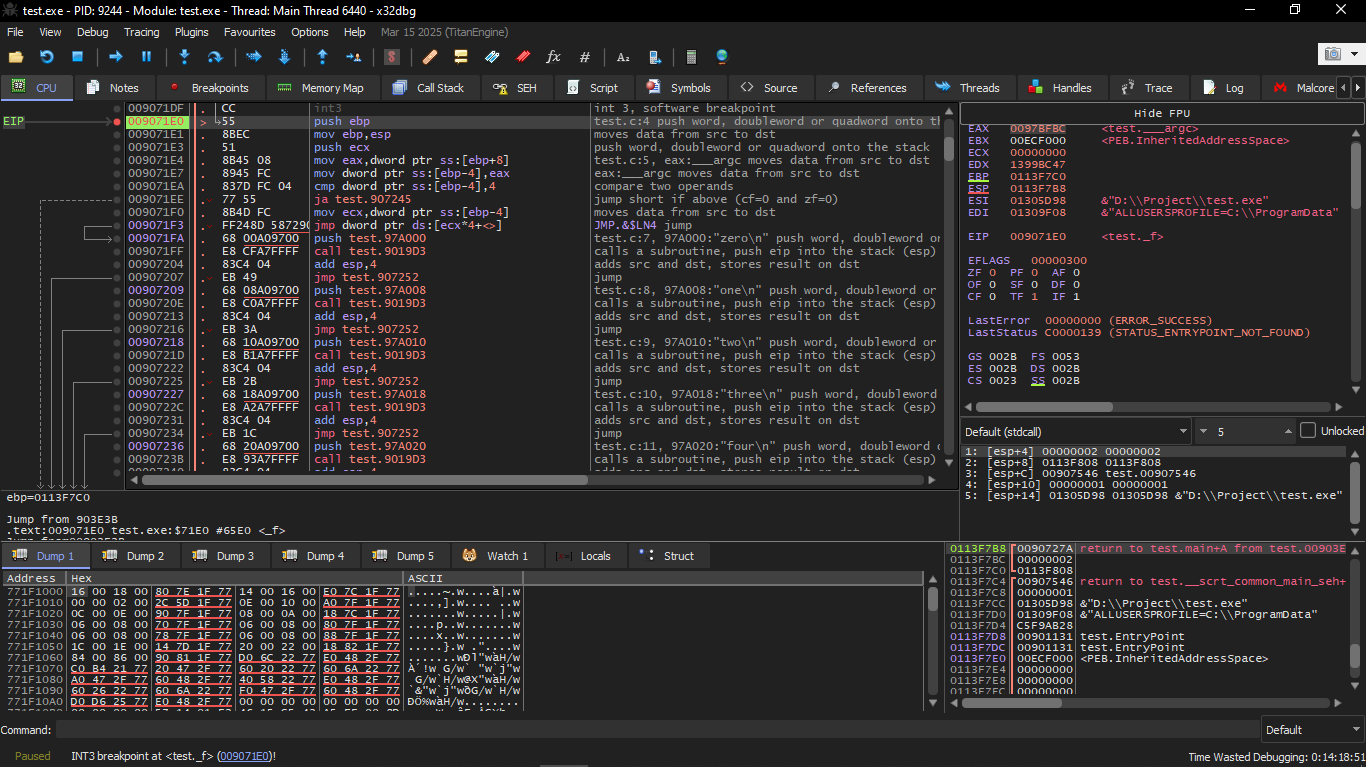
The input value of the function (2) is loaded into EAX:
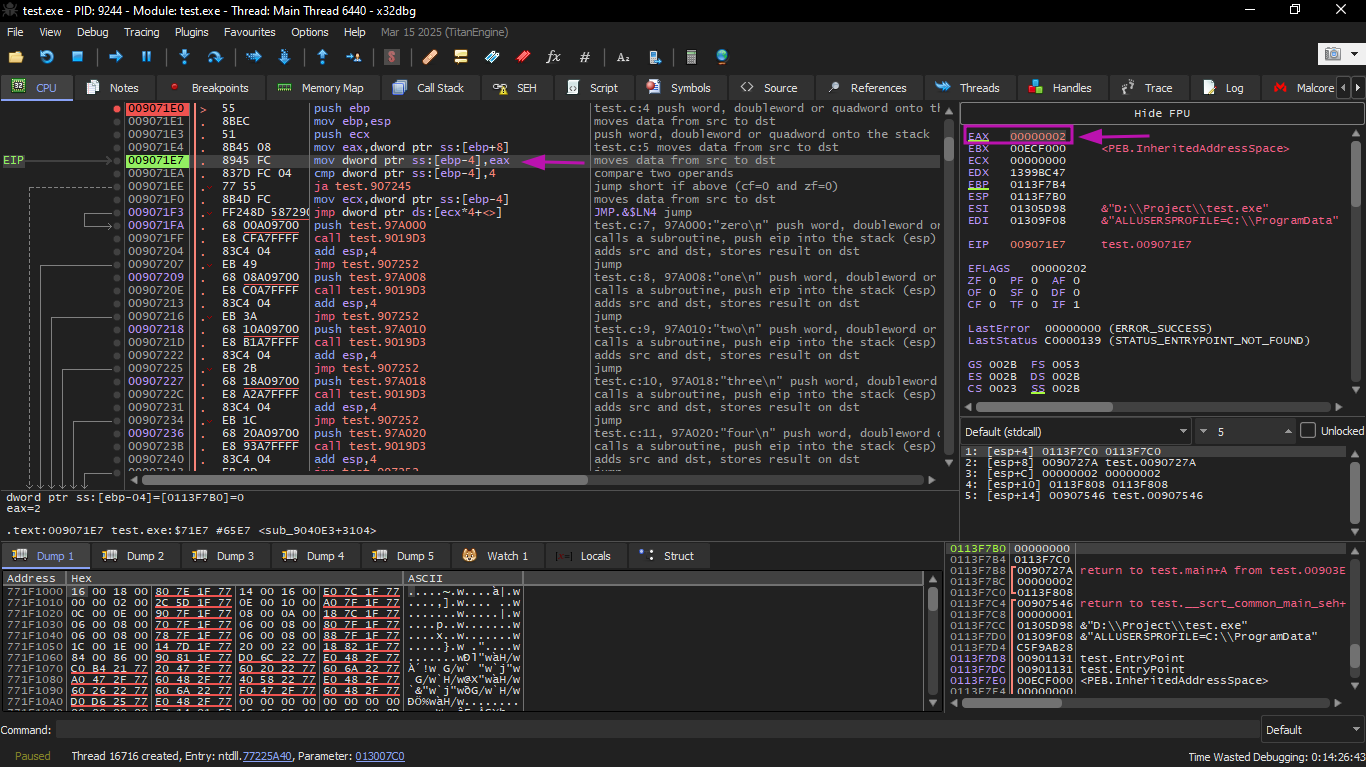
Then the input value is checked: is it greater than 4? If not, the "default" jump is not taken:
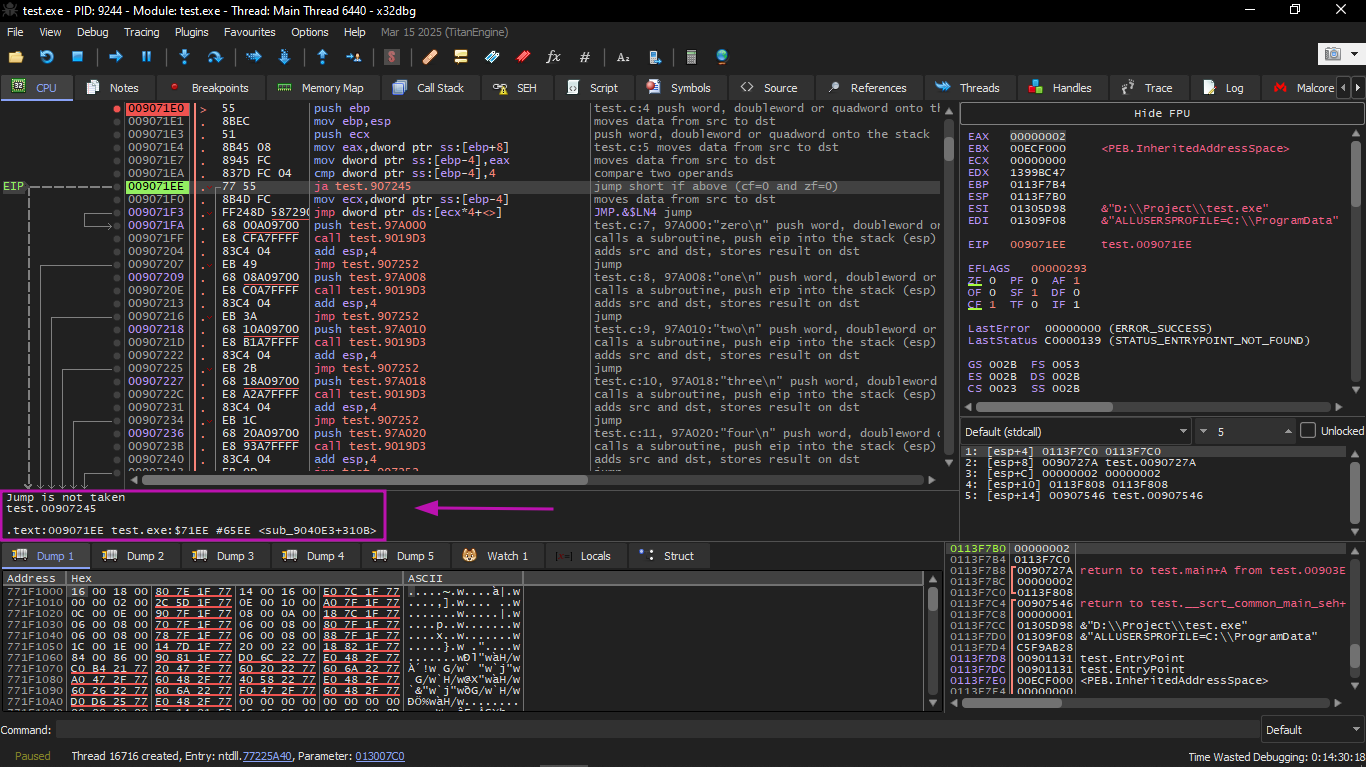
Then we can view the jumptable by choosing Follow in Dump → Constant:
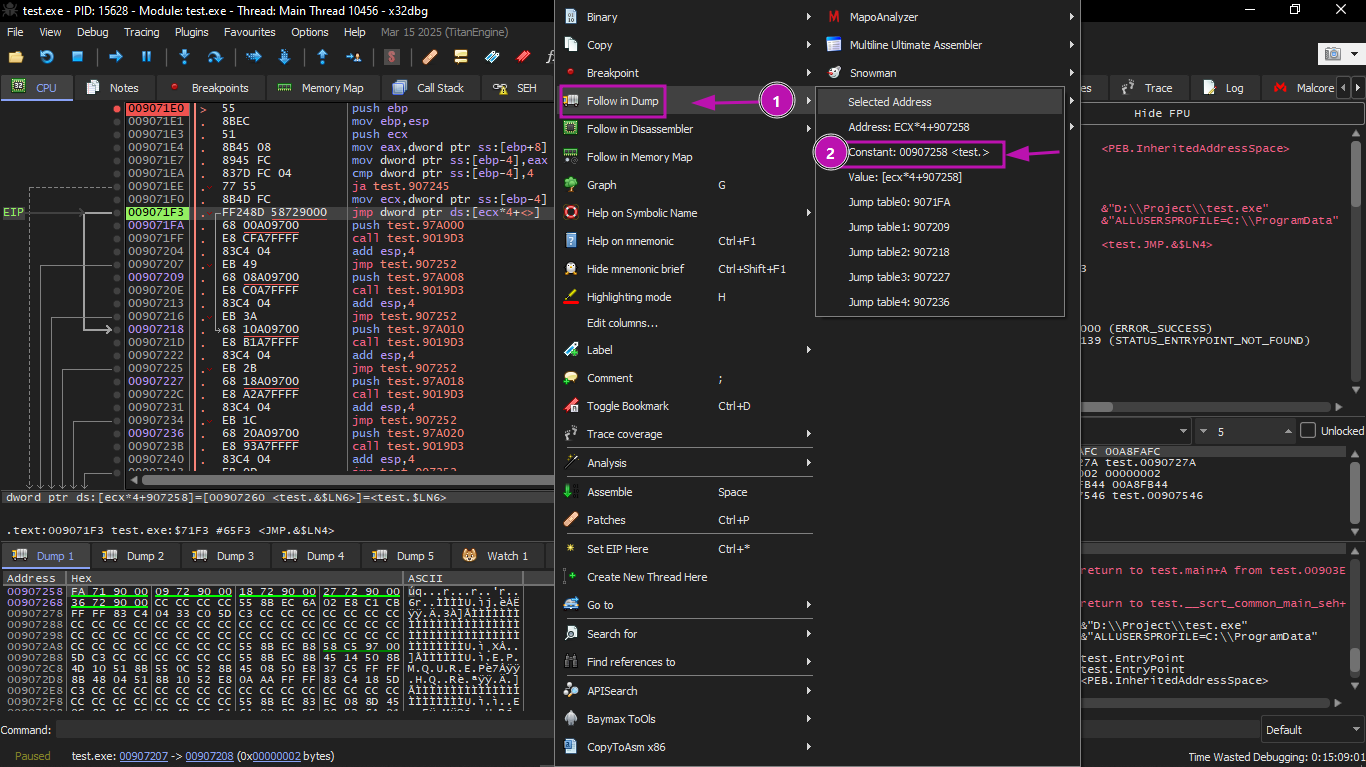
Now we see the jumptable in the data window. These are 5 32-bit values.
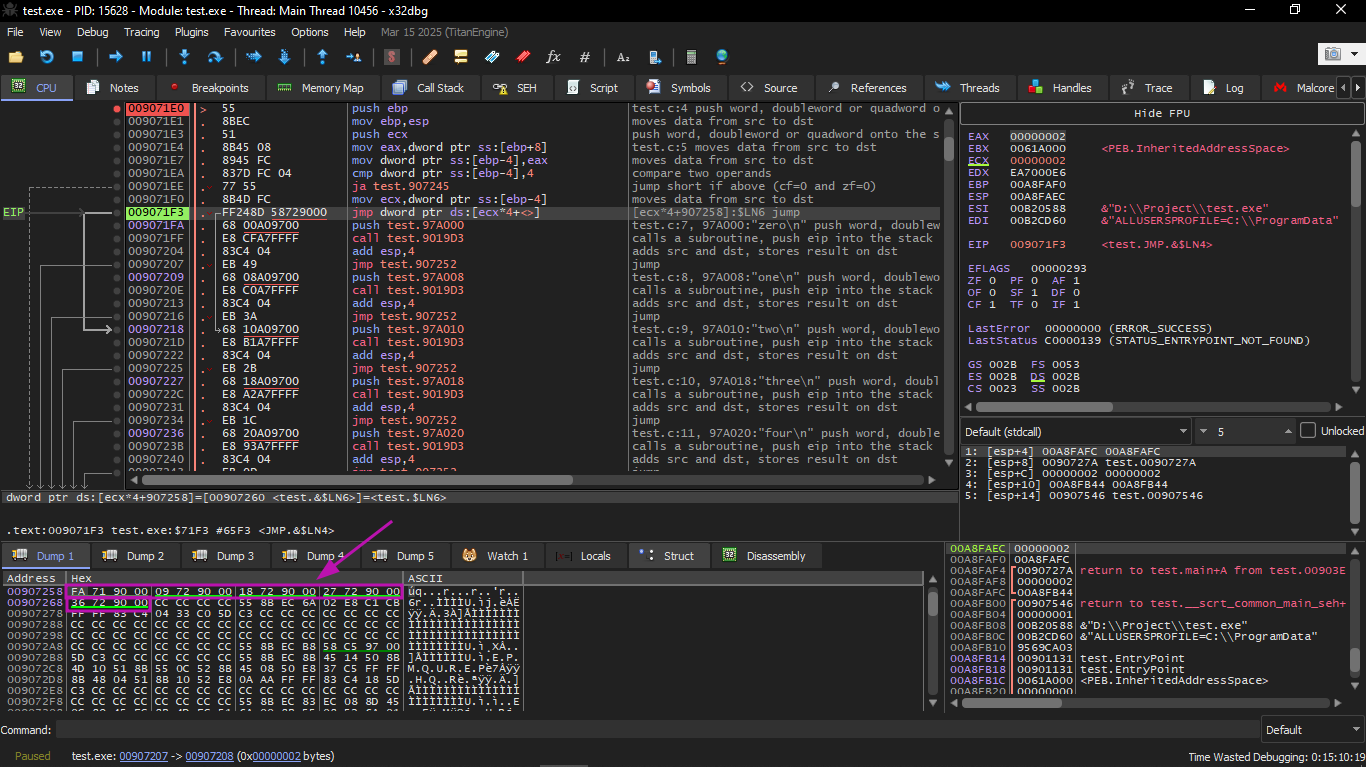
Now ECX is 2, so the third element (index 2) in the table will be used.
After the jump we are at 0x907218 — the code that prints "two" will now execute:
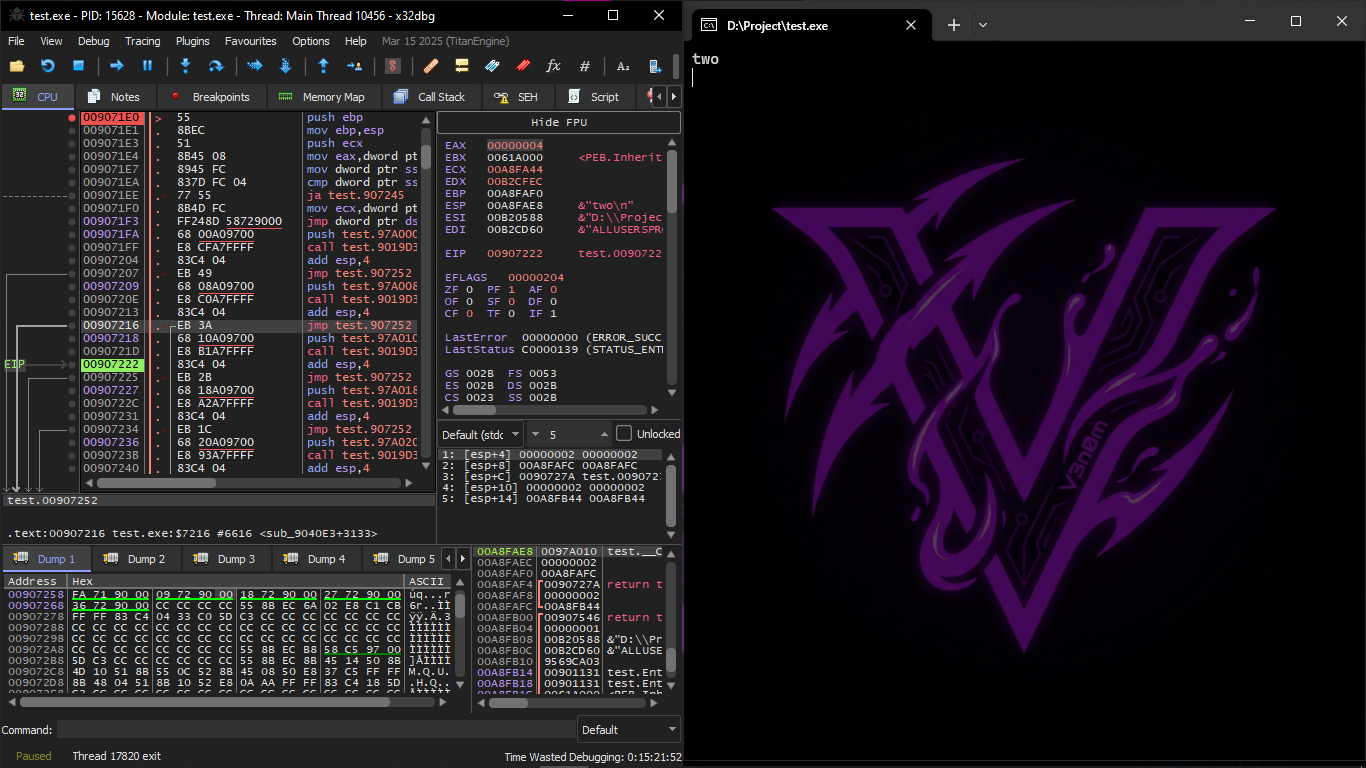
Non-optimizing GCC
Let us see what GCC 4.4.1 produces:
public ff proc nearvar_18 = dword ptr -18harg_0 = dword ptr 8
push ebp mov ebp, esp sub esp, 18h
cmp [ebp+arg_0], 4 ; compare input with 4 ja short loc_8048444 ; if greater, jump to default
mov eax, [ebp+arg_0] ; load input shl eax, 2 ; multiply by 4 (shift left by 2) mov eax, ds:off_804855C[eax] ; load address from table jmp eax ; jump to loaded address
loc_80483FE: ; case 0 mov [esp+18h+var_18], offset aZero ; "zero" call _puts jmp short locret_8048450
loc_804840C: ; case 1 mov [esp+18h+var_18], offset aOne ; "one" call _puts jmp short locret_8048450
loc_804841A: ; case 2 mov [esp+18h+var_18], offset aTwo ; "two" call _puts jmp short locret_8048450
loc_8048428: ; case 3 mov [esp+18h+var_18], offset aThree ; "three" call _puts jmp short locret_8048450
loc_8048436: ; case 4 mov [esp+18h+var_18], offset aFour ; "four" call _puts jmp short locret_8048450
loc_8048444: ; default case mov [esp+18h+var_18], offset aSomethingUnkno ; "something unknown" call _puts
locret_8048450: leave retnf endp
off_804855C dd offset loc_80483FE ; jump table dd offset loc_804840C dd offset loc_804841A dd offset loc_8048428 dd offset loc_8048436
This is almost the same thing, with a small difference: the argument arg_0 is multiplied by 4 by shifting left by 2 bits (which is essentially the same as multiplying by 4), then the label address is taken from the array off_804855C, stored in EAX, and then JMP EAX performs the actual jump.
ARM: Optimizing Keil 6/2013 (ARM mode)
.text:00000174 f2 CMP R0, #5 ; compare input with 5 (max case + 1) ADDCC PC, PC, R0,LSL#2 ; if less than 5, add (input * 4) to PC B default_case ; otherwise jump to default
loc_180: ; case 0 B zero_case
loc_184: ; case 1 B one_case
loc_188: ; case 2 B two_case
loc_18C: ; case 3 B three_case
loc_190: ; case 4 B four_case
zero_case: ADR R0, aZero ; load "zero" B loc_1B8
one_case: ADR R0, aOne ; load "one" B loc_1B8
two_case: ADR R0, aTwo ; load "two" B loc_1B8
three_case: ADR R0, aThree ; load "three" B loc_1B8
four_case: ADR R0, aFour ; load "four"
loc_1B8: B __2printf ; call printf
default_case: ADR R0, aSomethingUnkno ; load "something unknown" B loc_1B8 ; jump to printfThis code exploits the fact that all instructions in ARM mode are fixed size (4 bytes).
Recall that the maximum value of a is 4 and any larger value will cause the string "something unknown\n" to be printed.
The first instruction CMP R0, #5 compares the input value of a with 5.
The next instruction ADDCC PC, PC, R0,LSL#2 executes only if R0 < 5 (CC = Carry clear / Less than).
Thus, if ADDCC did not execute (i.e., R0 ≥ 5 case), a jump to label default_case occurs.
But if R0 < 5 and ADDCC executed, what happens is: the value of R0 is multiplied by 4. In fact, LSL#2 at the end of the instruction means "shift left by 2 bits". But as we will see later in the "Shifts" section, shift left by 2 bits equals multiplication by 4.
Then R0 * 4 is added to the current value in PC, thus jumping to one of the B (Branch) instructions below.
At the moment of executing ADDCC, the value of PC is 8 bytes (0x180) ahead of the address of the ADDCC instruction itself (0x178), or in other words, two instructions ahead.
This is how the pipeline works in ARM processors: when ADDCC is executed, the processor is already processing the instruction two steps ahead, so PC points there. This point must be memorized.
If a = 0, 0 is added to the PC value, and the actual PC value (which is 8 bytes ahead) is written to PC, resulting in a jump to label loc_180, which is 8 bytes ahead of where the ADDCC instruction is.
If a = 1: PC + 8 + a*4 = PC + 8 + 4 = PC + 12 = 0x184, which is the address of label loc_184.
With each increment of a, the resulting PC value increases by 4. And 4 is the length of an instruction in ARM mode, and also the length of each B instruction, of which there are 5 in a row.
Each of these five B instructions transfers control forward to what is programmed in the switch().
Loading the appropriate string pointer happens there, etc.
ARM: Optimizing Keil 6/2013 (Thumb mode)
.text:000000F6 f2 PUSH {R4,LR} MOVS R3, R0 BL __ARM_common_switch8_thumb ; call helper function DCB 5 ; number of cases (excluding default) DCB 4, 6, 8, 0xA, 0xC, 0x10 ; offsets for each case
zero_case: ADR R0, aZero B loc_118
one_case: ADR R0, aOne B loc_118
two_case: ADR R0, aTwo B loc_118
three_case: ADR R0, aThree B loc_118
four_case: ADR R0, aFour
loc_118: BL __2printf POP {R4,PC}
default_case: ADR R0, aSomethingUnkno B loc_118It is not possible to be sure that all instructions in Thumb and Thumb-2 have the same size.
One could also say that in these modes instructions have variable length, like in x86.
Therefore, a special table is added containing information about the number of cases (excluding default-case) and also the offset for each case with the label to which control should go in the appropriate case.
There is a special function here to handle the table and transfer control, named __ARM_common_switch8_thumb. It starts with BX PC, whose purpose is to switch the processor to ARM mode.
Then the function responsible for handling the table is executed. It is too advanced to explain here now, so let us leave it.
Interestingly, the function uses the LR register as a pointer to the table.
Indeed, after calling this function, LR contains the address after the instruction BL __ARM_common_switch8_thumb, which is where the table starts.
It is also noteworthy that the code is generated as a separate reusable function, meaning the compiler does not emit the same code for each switch().
IDA successfully understood it as a service function and table, and added comments to the labels like: jumptable 000000FA case 0.
MIPS
f: lui $gp, (__gnu_local_gp >> 16)
sltiu $v0, $a0, 5 ; set $v0 to 1 if input < 5 bnez $v0, loc_24 ; if true, jump to table handling la $gp, (__gnu_local_gp & 0xFFFF) ; branch delay slot
; input >= 5: default case lui $a0, ($LC5 >> 16) ; load "something unknown" lw $t9, (puts & 0xFFFF)($gp) or $at, $zero ; NOP jr $t9 ; call puts la $a0, ($LC5 & 0xFFFF) ; delay slot
loc_24: la $v0, off_120 ; load address of jump table
sll $a0, 2 ; multiply input by 4 addu $a0, $v0, $a0 ; add to table base
lw $v0, 0($a0) ; load target address from table or $at, $zero ; NOP
jr $v0 ; jump to target or $at, $zero ; delay slot, NOP
sub_44: ; case 3 lui $a0, ($LC3 >> 16) ; "three" lw $t9, (puts & 0xFFFF)($gp) or $at, $zero jr $t9 la $a0, ($LC3 & 0xFFFF)
sub_58: ; case 4 lui $a0, ($LC4 >> 16) ; "four" lw $t9, (puts & 0xFFFF)($gp) or $at, $zero jr $t9 la $a0, ($LC4 & 0xFFFF)
sub_6C: ; case 0 lui $a0, ($LC0 >> 16) ; "zero" lw $t9, (puts & 0xFFFF)($gp) or $at, $zero jr $t9 la $a0, ($LC0 & 0xFFFF)
sub_80: ; case 1 lui $a0, ($LC1 >> 16) ; "one" lw $t9, (puts & 0xFFFF)($gp) or $at, $zero jr $t9 la $a0, ($LC1 & 0xFFFF)
sub_94: ; case 2 lui $a0, ($LC2 >> 16) ; "two" lw $t9, (puts & 0xFFFF)($gp) or $at, $zero jr $t9 la $a0, ($LC2 & 0xFFFF)
off_120: .word sub_6C ; case 0 .word sub_80 ; case 1 .word sub_94 ; case 2 .word sub_44 ; case 3 .word sub_58 ; case 4
The new instruction for us here is SLTIU ("Set on Less Than Immediate Unsigned"). It is the same as SLTU ("Set on Less Than Unsigned"), but the "I" means "immediate", i.e., a number is written directly in the instruction.
BNEZ means "Branch if Not Equal to Zero". The code is very close to other ISAs.
SLL ("Shift Word Left Logical") multiplies by 4. MIPS is ultimately a 32-bit CPU, so all addresses in the jumptable are 32-bit addresses.
Conclusion
The general structure of switch():
MOV REG, inputCMP REG, 4 ; maximal number of casesJA defaultSHL REG, 2 ; shift for multiplication by 4 (x64 uses 3 bits)MOV REG, jump_table[REG]JMP REG
case1: ; do something JMP exit
case2: ; do something JMP exit
case3: ; do something JMP exit
case4: ; do something JMP exit
case5: ; do something JMP exit
default: ...
exit: ....
jump_table dd case1 dd case2 dd case3 dd case4 dd case5The jump to the address in the jump table can also be done using the instruction:
JMP jump_table[REG*4] or JMP jump_table[REG*8] in x64.
And the jumptable is just an array of pointers.
If this article helped you, please share it with others!
Some information may be outdated