







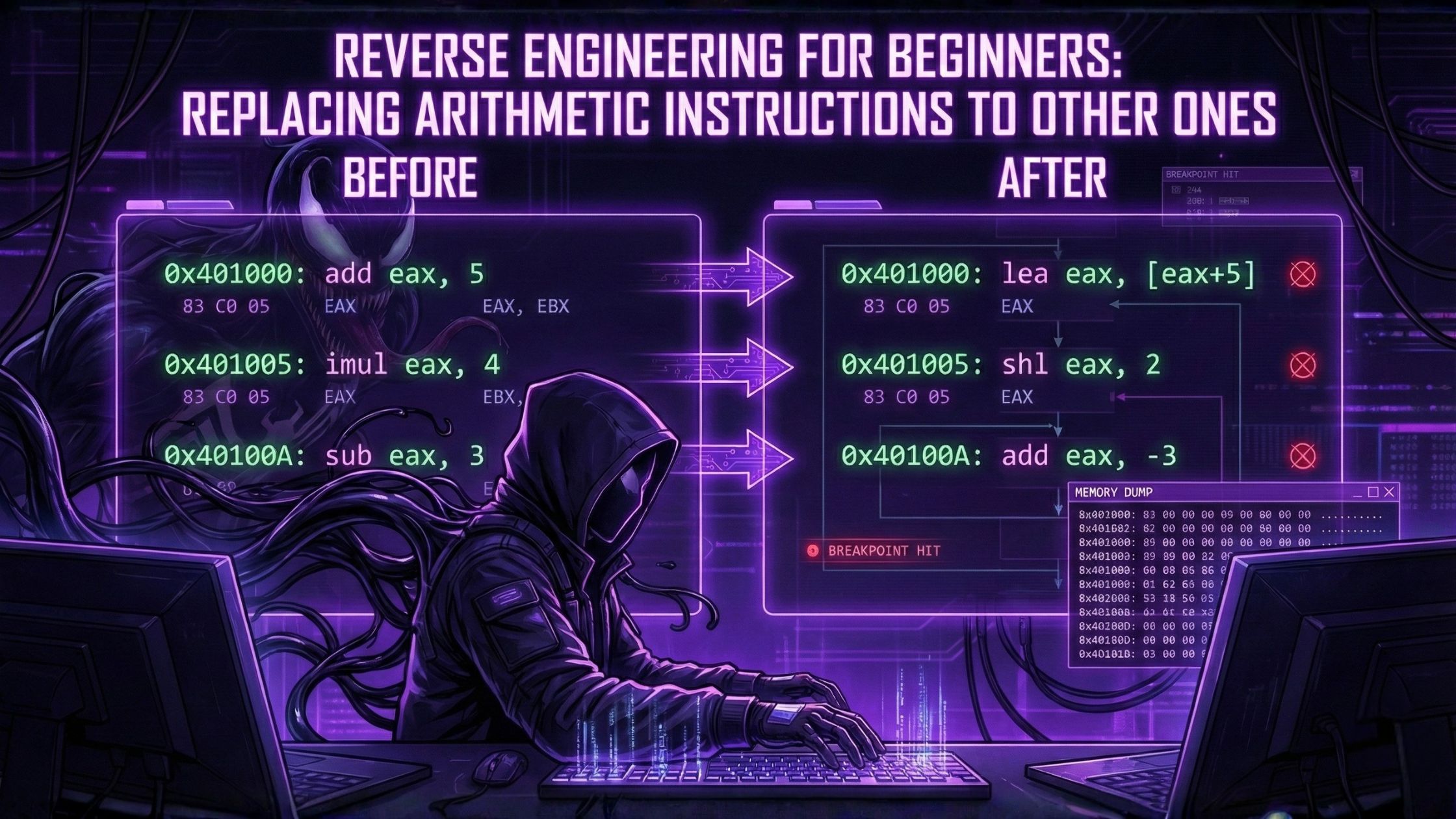
For the sake of optimization, an instruction can be replaced with another instruction, or even with a group of instructions.
For example, ADD and SUB can replace each other.
Also, the LEA instruction is often used for simple arithmetic calculations.
1.24.1 Multiplication

Multiplication using addition
A simple example:
Multiplication by 8 was replaced with 3 addition instructions, which do the same thing.
It is obvious that the MSVC optimizer decided that this code could be faster.
Multiplication using shifting
Multiplication and division instructions by numbers that are powers of 2 are often replaced with shift instructions.
The instruction named SHL is an abbreviation for SHift Left.
Multiplication by 4 is just shifting the number left by 2 bits and adding two zero bits on the right (as the least significant bits).
This is like multiplying 3 by 100 — we simply add two zeros on the right.
This is how the shift left instruction works:

The bits added on the right are always zeros.
To make it clearer in case you got confused:
Let us say:
3 in binary:
If we do:
Meaning shift left twice:
The result 00001100 in decimal = 12
Which is indeed: 3 * 4 = 12
Multiplication by 4 on ARM
Multiplication by 4 on MIPS
SLL means "Shift Left Logical".
Multiplication using shifting, subtracting, and adding
It is still possible to get rid of multiplication when multiplying by numbers like 7 or 17, also using shifting. The math used here is relatively simple.
32-bit
x86
ARM
Keil in ARM mode exploits the second operand shift modifiers:
But there are no such modifiers in Thumb mode. It also cannot optimize f2():
MIPS
64-bit
x64
ARM64
GCC 4.9 for ARM64 is also concise, thanks to shift modifiers:
Booth’s multiplication algorithm
There was a time when computers were big and expensive to the point that some did not have hardware support for multiplication inside the CPU, like the Data General Nova.
When multiplication was needed, it could be done at the software level, for example using Booth’s multiplication algorithm.
This is a multiplication algorithm that uses only addition and shifts. What modern optimizing compilers do is not the same thing, but the goal (multiplication) and resources (faster operations) are the same.
1.24.2 Division

Division using shifts
An example of division by 4:
We get (MSVC 2010):
The SHR (SHift Right) instruction in this example shifts the number right by 2 bits.
The two bits that were freed on the left (most significant bits) are filled with zeros.
The two bits on the right (least significant bits) are discarded.
In fact, these two discarded bits are the division remainder.
The SHR instruction works exactly like SHL, but in the opposite direction.

It is easy to understand if you imagine the number 23 in the decimal system.
23 can be easily divided by 10 by simply removing the last digit (3 — this is the remainder).
What remains after the operation is 2 as the quotient.
The remainder is discarded, but that's fine because we are working on integer values anyway, these are not real numbers!
Division by 4 on ARM
Division by 4 on MIPS
SRL means "Shift Right Logical".
If this article helped you, please share it with others!
Some information may be outdated